

1.背景与目的
YouTube(油管)是一个视频网站,但与一般的流媒体视频网站不同,例如国内的爱奇艺、优酷、腾讯等,它是一个用户生成内容(UGC)网站。因为依赖于用户发布、评论、观看等参与行为,所以优质内容的重要性显而易见。
该数据集包含了数月(2017年11月14日——2018年6月14日)的YouTube每日热门视频的数据,每天最多列出200个热门视频。数据包括视频标题、频道标题、发布时间、标签、观看次数、喜欢和不喜欢、描述以及评论数等字段。
通过分析数据集内热门视频的数据,探索其特征及规律,一方面挖掘用户原创内容的市场需求及喜好,另一方面呈现热门视频的影响因素。为内容产品的打造与运营提供一些维度的数据依据。
2.数据定义
数据来源于Kaggle的<Trending YouTube Video Statistics>中加拿大地区的数据文件,文件包含一个数据集csv文件和一个json文件。数据集内共40881条数据,包含以下16个字段:
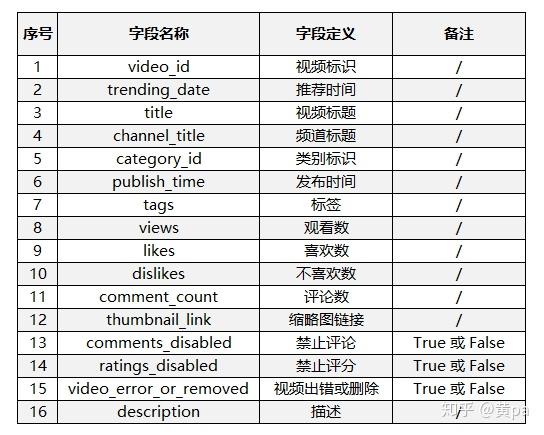
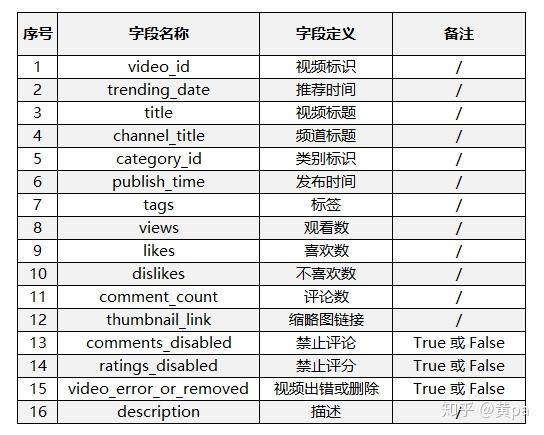
3.提出问题及分析思路
3.1提出问题
- 不同类别视频的视频数如何分布?
- 多次推荐的视频数如何分布?
- 连续变量间是否会产生影响?
- 不同类别视频之间的连续变量数据是否存在差异性?
- 从发布至首次推荐需要多长的时间?
- 视频发布时间是否存在规律?集中于什么时间?
3.2分析思路
多维度拆解梳理思路,构建分析指标。
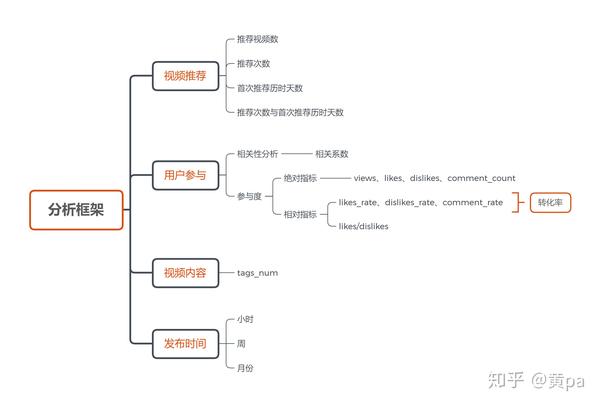
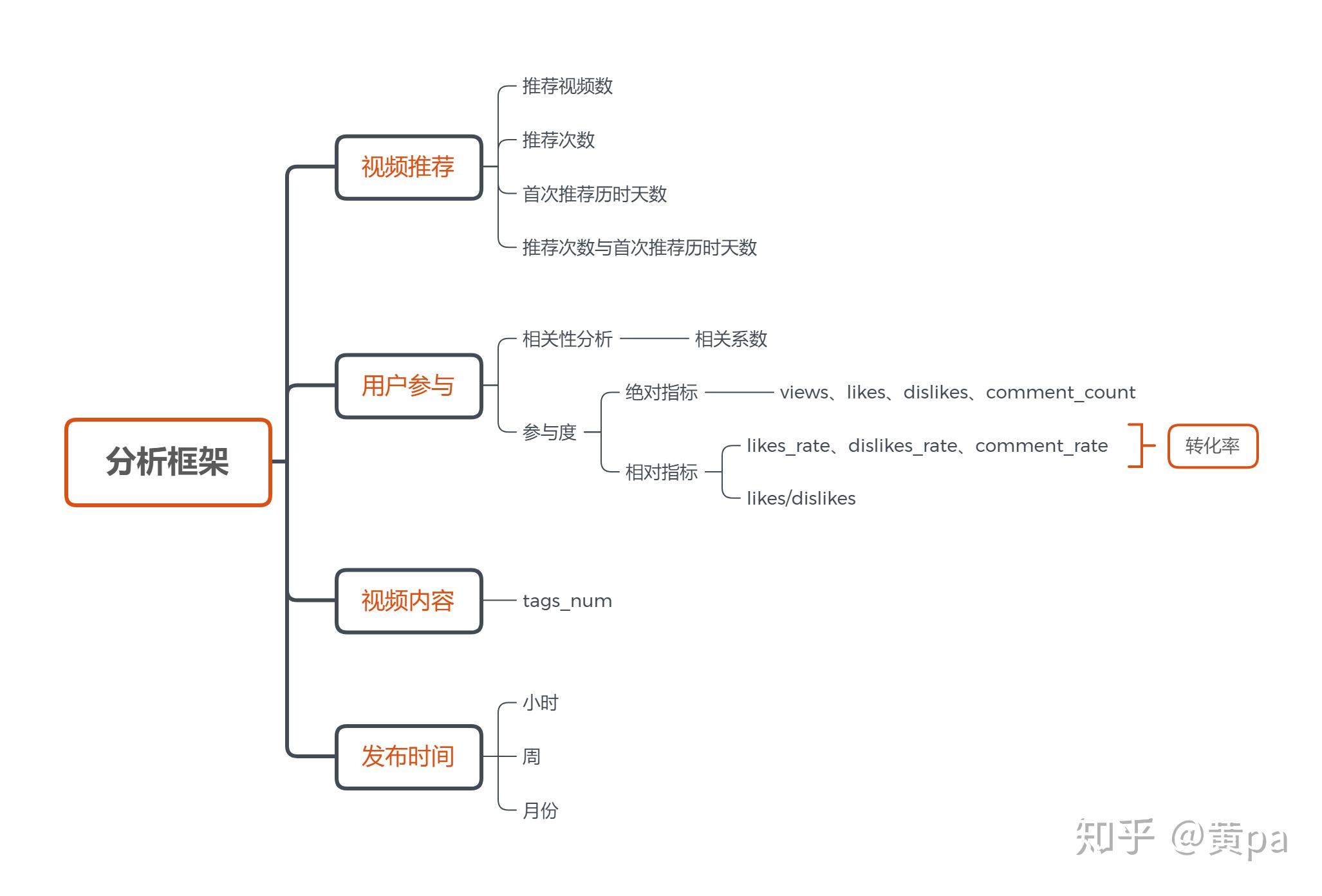
4.数据分析
4.1文件转换
4.1.1数据集编码转换


通过excel查看此数据,发现存在乱码及错位,应该是编码的问题,在此用python处理。




4.1.2json文件转换
通过Python处理,导出为csv文件,复制粘贴进上述数据csv文件中,再导出为xlsx文件。
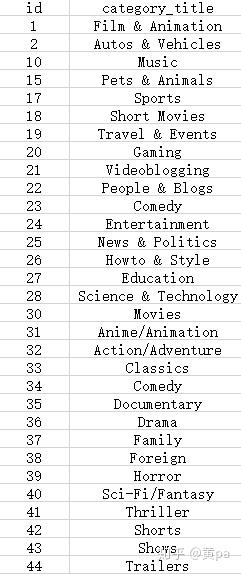
新建列category_title,用VLOOKUP函数填充此列。
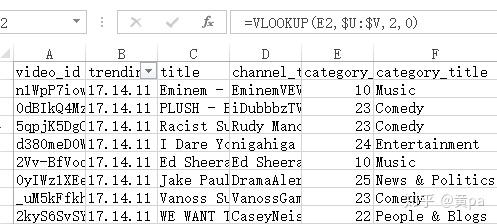
4.2数据处理
4.2.1数据字段提取
现数据集加上category_title后共包含17个字段,从中提取出可供分析的核心字段,隐藏category_id、thumbnail_link、comments_disabled、ratings_disabled、video_error_or_removed这5个字段,分析剩余的11个字段。
4.2.2数据清洗
(1)缺失值
若某一字段的缺失数据较多(例如超过50%),为了数据分析的准确性一般会考虑删除,但如果是重要性较强的字段则考虑通过一些方法填充(例如其他字段的关联信息、机器学习等)。
Excel可以选取每列后看右下角的计数值判断有无缺失值,计数值与大多数列的计数值不相等则有缺失值,此数据集的category_title和description均有缺失值。
description综合考虑重要性、技术原因以及原本空白的可能性后在这里不做处理。category_title筛选出缺失值后对照category发现是category_id=29的数据行有缺失值,原因是加拿大地区的json文件内未包含29的数据。
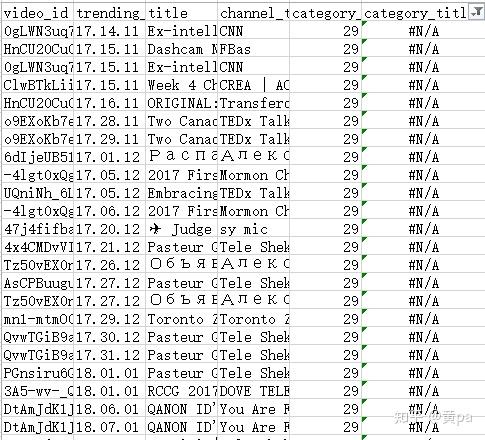
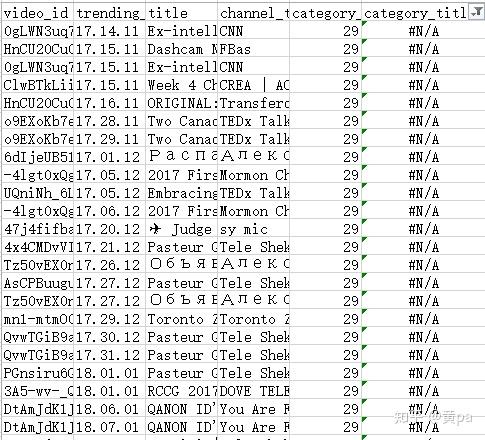
查看其他地区的json数据,美国地区的json文件内有id=29的数据,直接将此id和title复制粘贴到Excel数据集的相应列后更新category_title。

(2)错误值(异常值)
通过条件格式-突出显示单元格规则-其他规则,将全表的错误值填充为红色,每列按颜色筛选即可得到错误值。
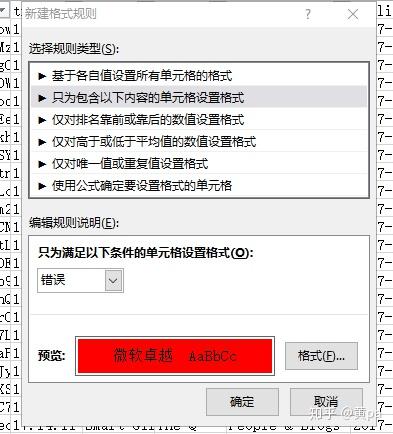

观察错误值发现错误原因是单元格首字符为=,例如=-MzKm69EKfs,默认为公式但无法识别出错,解决方法是替除掉=。
(3)一致化
一致化指的是数据值是否有统一的标准或命名。多一个符号或缺少非关键字但代表的是相同值的数据需要进行一致化处理。此数据集不做此处理。
(4)重复值
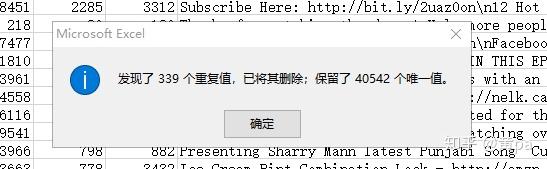
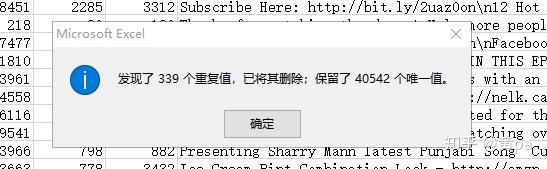
第一步,复制此表的数据至新表内,命名为unique_id,unique_id-数据-删除重复项,删除以video_id为判断条件的重复值数据,得到24226个唯一值。
第二步,将此表命名为unique,重复值定义为video_id 、trending_date均相同的数据,因为同一条视频是可能在不同的日期被推荐的,用以后续推荐次数相关的分析。
unique-数据-删除重复项,删除以video_id 和trending_date两列作为判断条件的重复值数据。
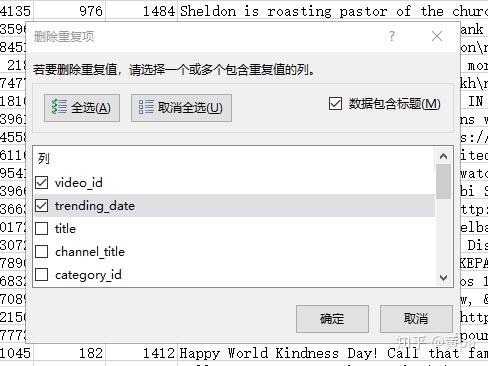
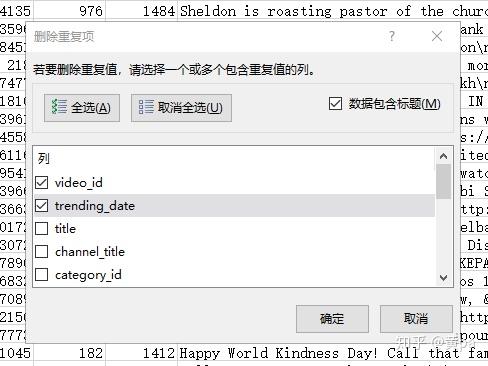
删除了339个重复值,得到40542个唯一值(不含字段标题)。
4.2.3数据转换
将特殊结构的数据转换为标准结构或统一结构。
(1)日期(trending_date)转换
trending_date中的值,例如17.14.11,代表了年日月,我们需要将其转换为表示年月日的yyyy-mm-dd格式。通过函数LEFT、RIGHT、MID以及&合并,即可得到yyyy-mm-dd格式的日期。


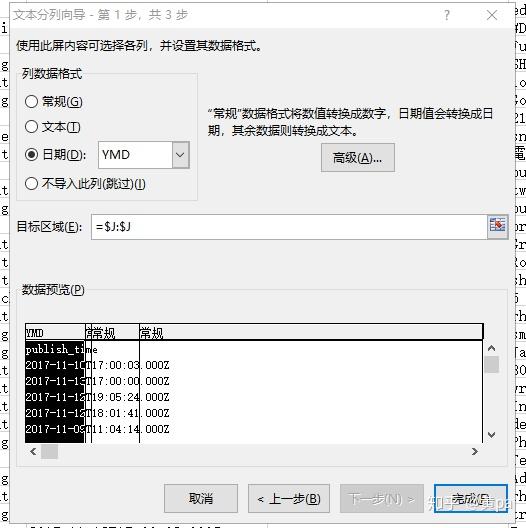
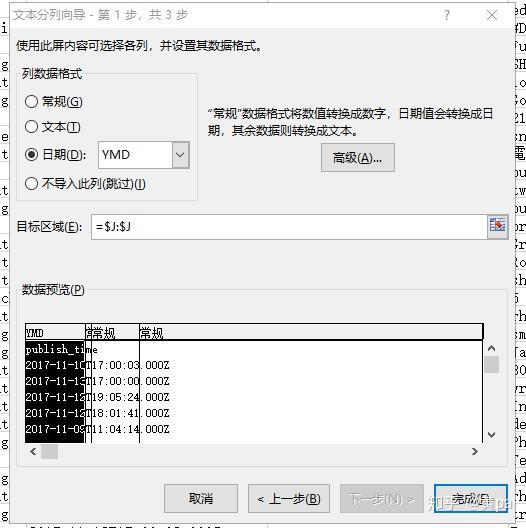
(2)时间(publish_time)拆分
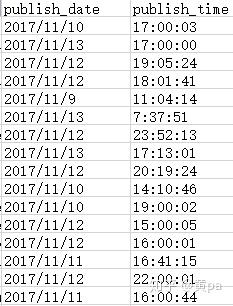
publish_time的值包含了日期和时间,例如2017-11-10T17:00:03.000Z,可以通过固定宽度或分隔符号对其分列,拆分成publish_date和publish_time两列。
(2)标签(tags)拆分
tags的内容是创作者填写的,而不是在有限选项内做选择,所以tags的内容不适合一般地分类汇总,可以考虑对每行的tags计数。


每行的标签用符号|分隔,除首项外还附带双引号,无标签的则用[none]表示。


创建标签数tags_num列,用IF判断单元格是否为[none],是则输出0,否则输出标签数(符号|的计数值+1)。
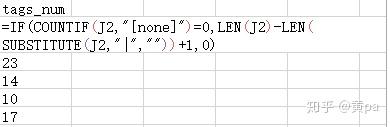
(4)添加列:推荐日期与发布日期的历时天数(pass_days)
pass_days = 推荐日期-发布日期
4.3数据分析与可视化
考虑到Excel不同版本间的差异,特别说明此文章内容使用的版本为Excel 2016。
4.3.1视频推荐
(1)类别推荐次数与视频数
视频数是表unique_id中的video_id数量,视频推荐次数是表unique中的video_id数量。
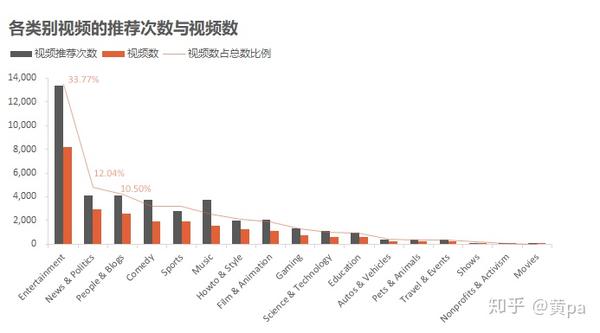
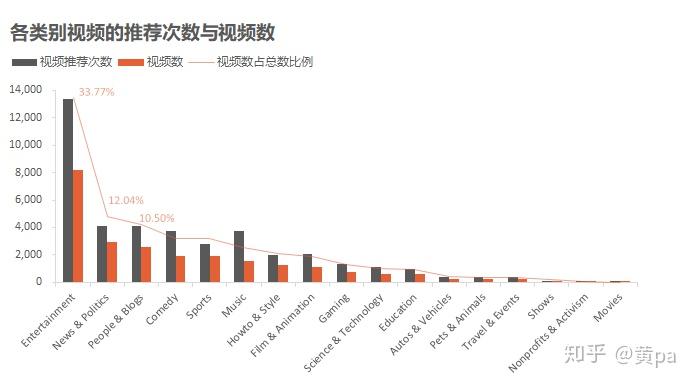
数据集中的视频类别共包含17个,数量前三名的类别分别是Entertainment、News&Politics、People&Blogs,共占比56.32%。其中,Entertainment的数量一骑绝尘,共8182个,占比33.77%。另外,Music和Comedy的推荐次数远高于其视频数,说明被推荐的热门视频中或是多次推荐的视频数量大或是部分视频的推荐次数多。
(2)推荐次数
运用函数countif()计算表unique_id中的video_id在表youtube中出现的次数,输出列times,再通过数据透视表汇总各推荐次数的视频数。
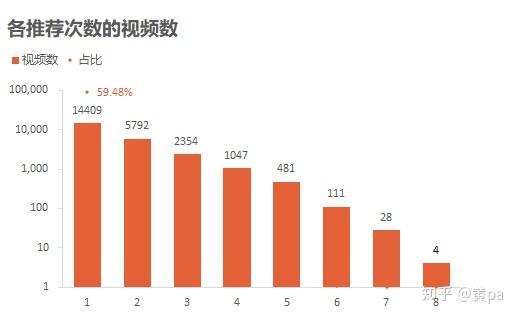
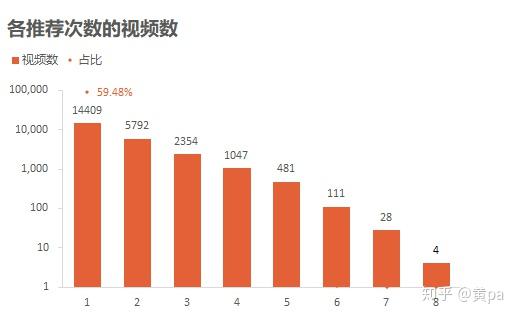
推荐次数最高为8次,随着推荐次数的递增,视频数的数量依次递减;1次的视频数为14409,超过了一半,占比59.48%,而8次的视频数仅为4。说明大部分的视频并没有被多次推荐,能达到最多推荐次数的更是凤毛麟角。
(3)首次推荐历时天数
通过数据透视表,行选择pass_days,值选择计数,即可得到汇总数。
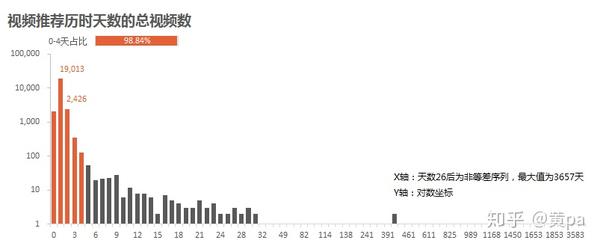
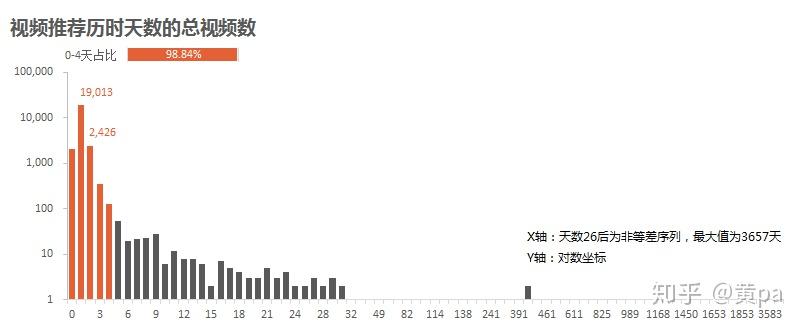
整体分布右偏,发布至推荐的历时天数集中在0-4天,占比98.84%;1天的总视频数最高,达到19,013个。可以说发布视频的4天后还未被推荐,则希望渺茫了。
(4)视频推荐次数与历时天数
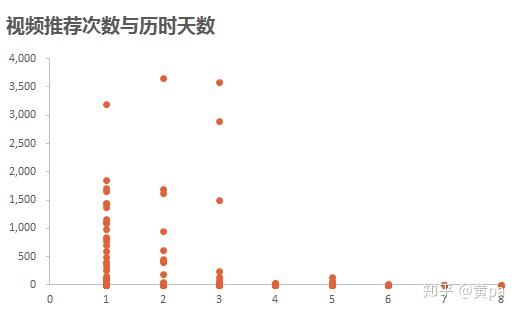
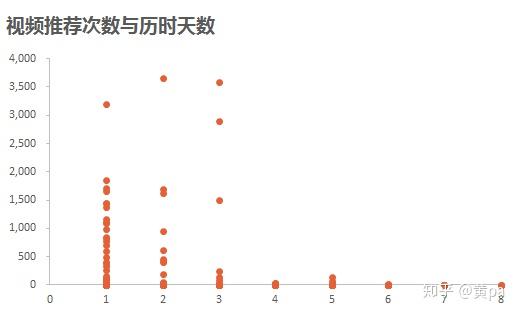
推荐次数为1-3次的视频,相较于次数为4-8次的视频,其首次推荐历时天数明显范围更大更分散;7-8次的视频,推荐历时天数不是0天就是1天。结合前述的分析,0-4天的视频占了绝大部分,但要成为推荐次数的王者,则必须在0或1天被首次推荐。
4.3.2相关系数
因为图表中不包含热力图,在此制作类似图表替代。数据-数据分析-相关系数选择需要分析的字段后可得到相关系数的数值,再选择数值区域后点击条件格式-新建规则-双色/三色刻度,即可得如下图所示图表:
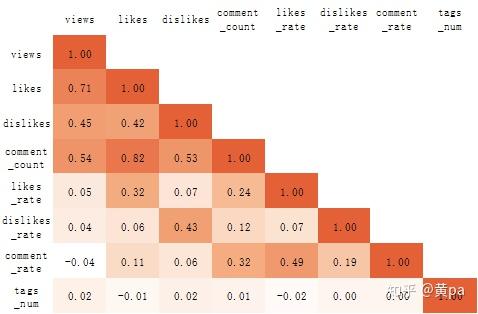
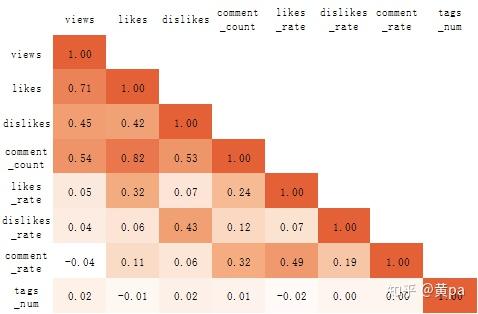
相关系数r的绝对值区间为[0,1],绝对值越接近1则相关程度越强;r为正值表示正相关,负值表示负相关。
- |r|≥0.8时,可视为两个变量之间高度相关;
- 0.5≤|r|<0.8时,可视为中度相关;
- 0.3≤|r|<0.5时,视为低度相关;
- |r|<0.3时,说明两个变量之间的相关程度极弱,可视为不相关。
在此图中,颜色越深则表示相关程度越高。由于分析的侧重点,在此只分析中高度相关。
- 高度相关:喜欢数(likes)与评论数(comment_count);
- 中度相关:观看数(views)与喜欢数(likes)、观看数(views)与评论数(comment_count)、不喜欢数(dislikes)与评论数(comment_count)。
总体而言,用户观看视频后更倾向于表达喜欢和评论,这或许就是能成为热门视频的视频魅力。用户的评论与对视频的喜欢与否均相关,但在表达喜欢的情况下会更积极地评论;如此看来,用户对喜欢会做出实际行动,而不喜欢则会部分选择沉默。
4.3.3参与度绝对指标
(1)总体参与度
选择数据-插入-图表-箱型图,由于数值量级的不同,从个位至亿位,而箱形图的坐标轴无法选择对数刻度,所以在此对原始值进行了对数处理,即log(原始值+1)。
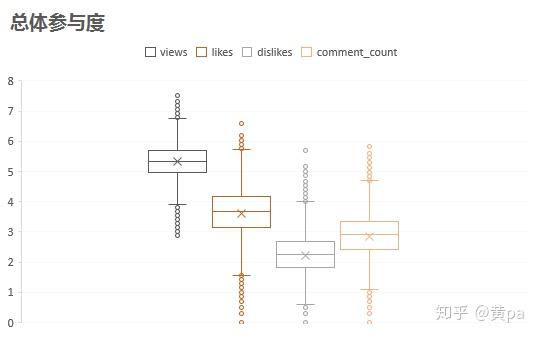
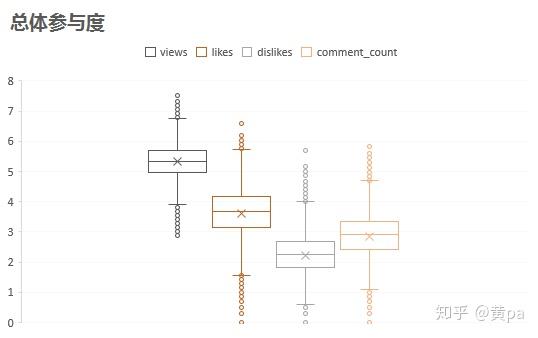
视频的Views、Likes、comment_count以及Dislikes的值依次下降,与相关系数的值的高低对应。
(2)Views
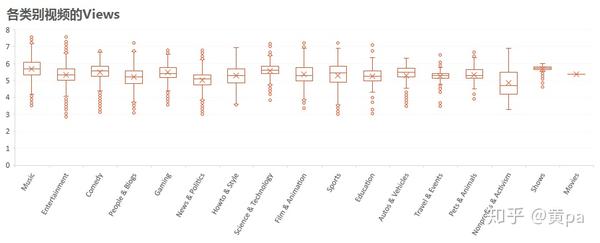
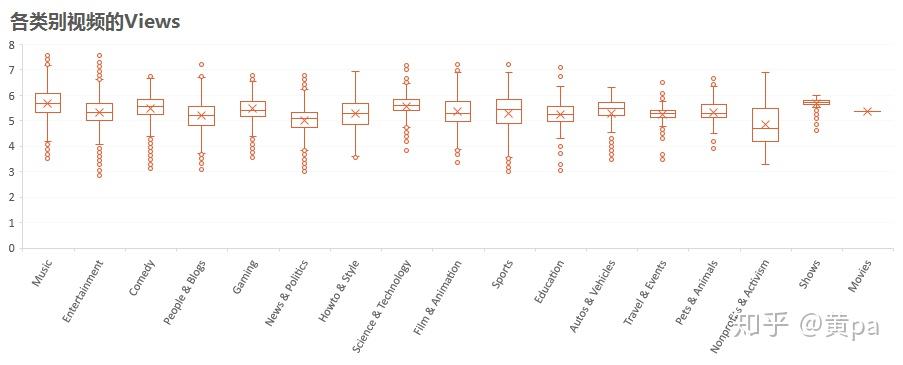
各类别视频中Science & Technology和Music的Views明显高于其他类别,Nonprofits & Activism的Views差距大。
(3)Likes
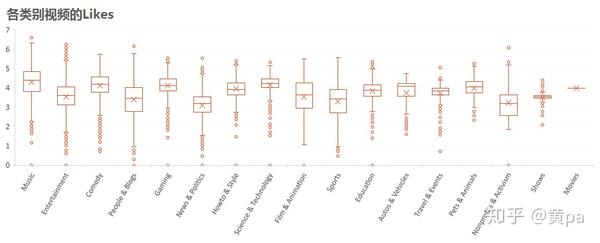
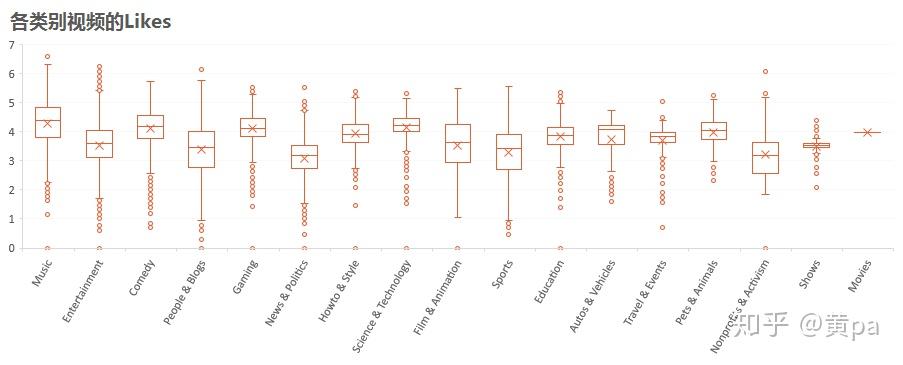
各类别视频中Music、Comedy、Gaming和Science&Technology的Likes的中位数和均值比较高,均超过10^4,其中Music的值最高。
(4)Dislikes
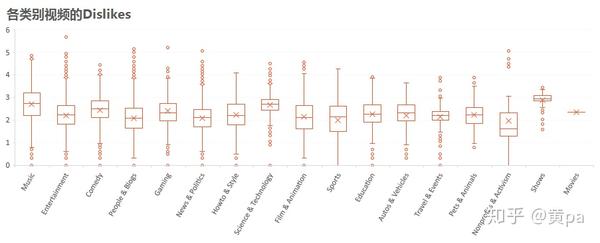
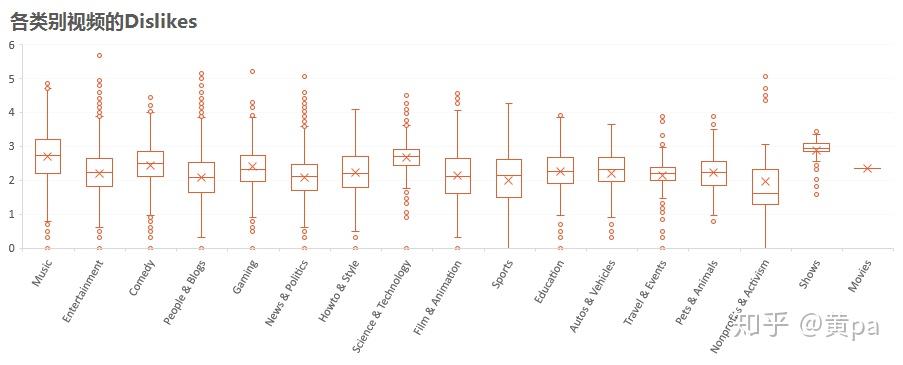
各类别视频中Shows的Dislikes最高,Science&Technology和Music次之。
(5)Comment_count
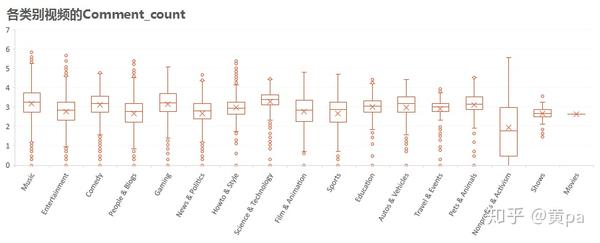
各类别视频中Science&Technology的Comment_count总体而言值最高,Pets&Animals、Music、Gaming和Comedy的Comment_count也比较高。
4.3.4参与度相对指标
通过频率分布图探索总体分布,选择数据-数据分析-直方图,输入区域选择相应的转化率数据,接受区域选择组间距数据(下图的组间距为1,值范围是[0,46],可以通过开始-填充-序列生成),确定即会输出频次。因为需要的不是直方图,所以没有勾选直方图。而频率分布图的纵坐标是频率/组间距,所以输出的频次还需除以总数据量再除以组间距(频次/24226/1)。
(1)参与转化率
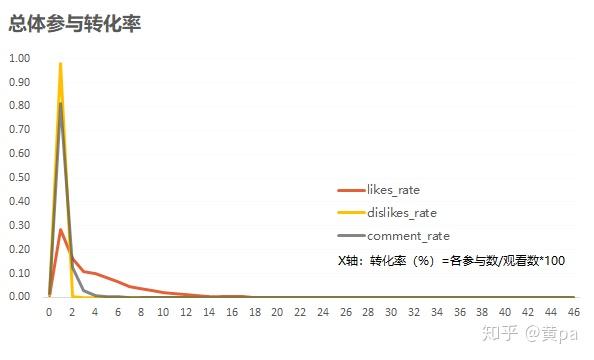
总体而言,视频的Dislikes_rate与Comment_rate都非常低,只有一小部分视频的Comment_rate稍高几个百分比,而Likes_rate明显远高于两者。三者的值均集中于区间(0,1](%),但Likes_rate的分布明显右偏且离散程度较大,另有大部分的值在区间(1,12](%);Dislikes_rate的值十分集中,绝大部分值在区间(0,1](%);Comment_rate与Dislikes_rate的分布十分相似,区别在于Comment_rate有一部分的值在区间(1,3](%)。再次说明用户观看这些热门视频后更多地是表达喜欢。
(2)Likes_rate
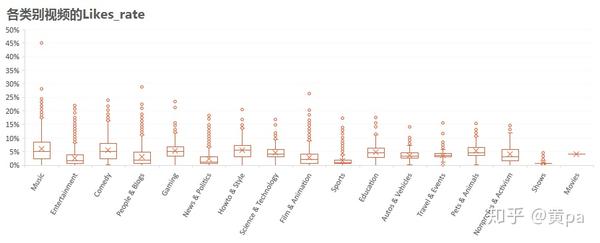
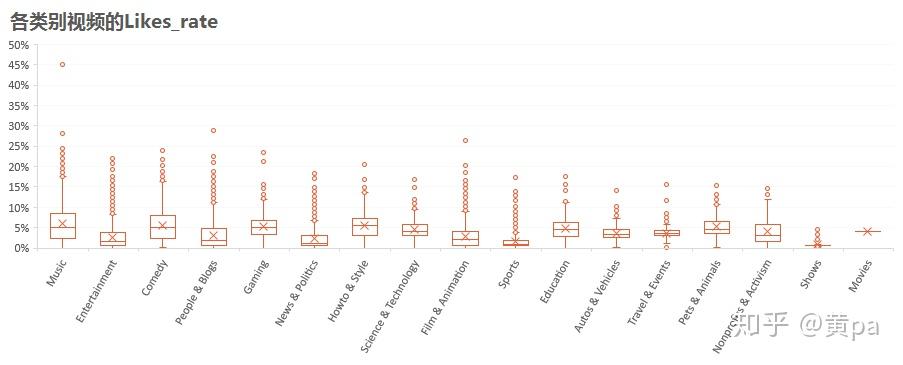
各类别视频中,Pets & Animals、Comedy、Gaming、Howto&Style和Music的Likes_rate较高,而Sports和Shows尤其低。
(3)Dislikes_rate
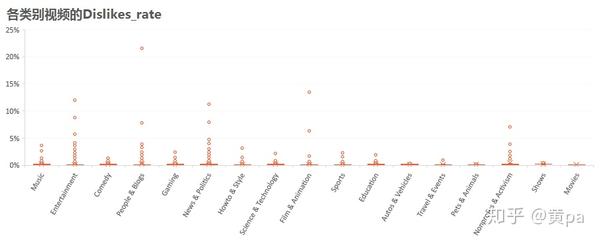
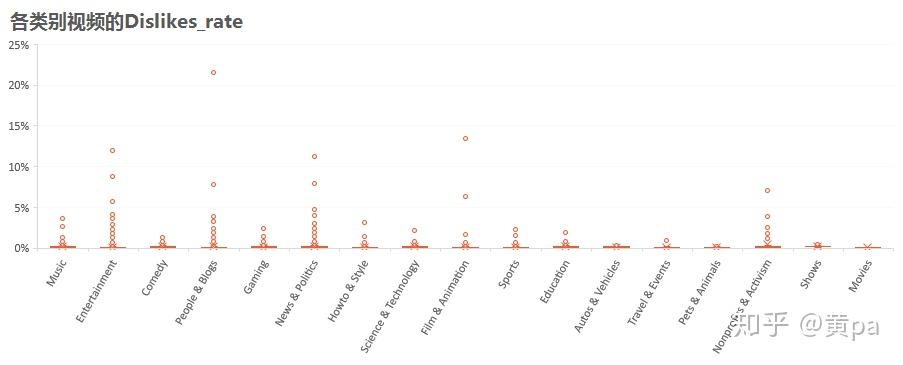
各类别视频的Dislikes_rate均非常低,尤其是Pets & Animals,而Comedy、Gaming、Howto&Style、Music各自的离群值也不高。
(4)Comment_rate
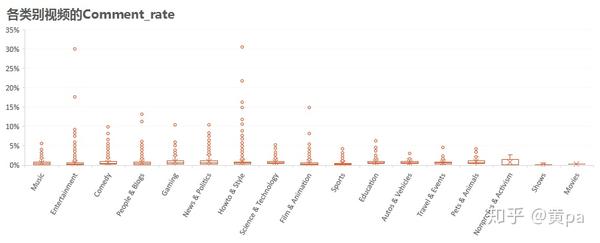
各类别视频的Comment_rate也非常低,Nonprofits & Activism、Pets & Animals和Comedy相对较高,Howto&Style和Entertainment有较多且较大的离群值。
(5)Likes/Dislikes
以防分母为0出现错误和分母不为0分子为0时不能更好地反映数据结果,在此对原始数据做了(L原始值+1)/(Dl原始值+1)处理。
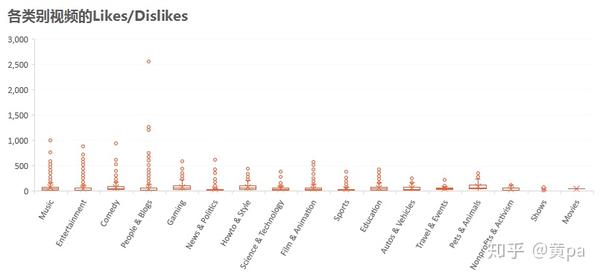
为了更好地展现数据结果,将个别极端离群值排除后选择值区间在[0,700]的数据。
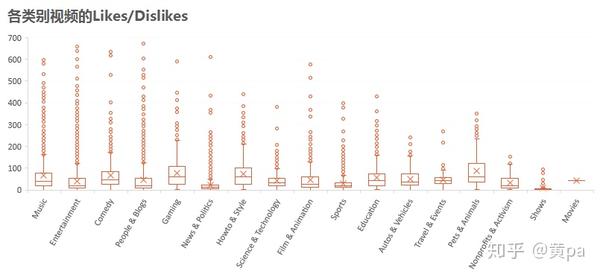
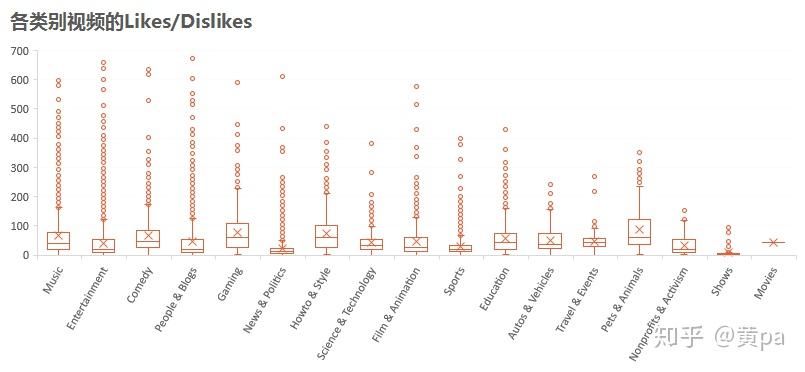
各类别视频中Pets & Animals的Likes/Dislikes总体而言值最高,Gaming和Howto & Style次之,这三类视频的观看用户喜欢的远高于不喜欢的。而Music、Entertainment、Comedy和People & Blogs的离群值特别多,也就是在整体一般的情况下,有一部分的视频表现出色,Likes/Dislikes的值尤其高。
4.3.5视频的Tags_num
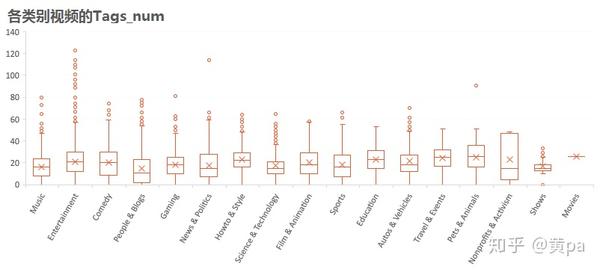
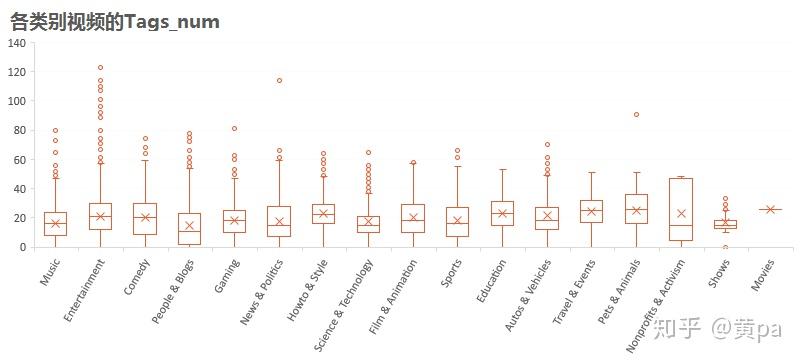
各类别视频的Tags_num均值均在10至30之间,其中People & Blogs的Tags_num中位数和均值是最低的,Entertainment最多离群值。说明大部分视频的Tags_num由于视频类别造成的差距并不大。
4.3.6发布时间
(1)月份
通过数据透视表,行选择发布日期,值选择计数,再点击透视表中日期列,右键创建组合-步长选择月,即可得到月份的汇总数。
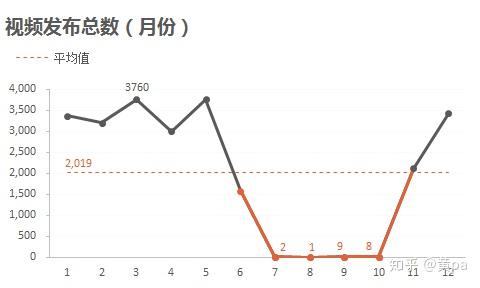
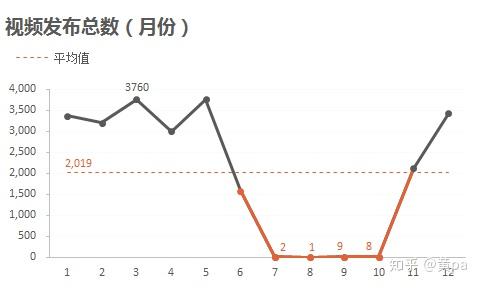
视频发布时间集中在11月-5月,发布的视频数均超过了均值2019,其中7-10月的视频数极低,只有个位数。可结合全网视频的发布月份进行分析,着重分析7-10月的低视频数原因。
(2)周
运用函数weekday()对列publish_date进行转换,即可得到日期周星期数。可用数据透视表或countif()汇总视频总数。
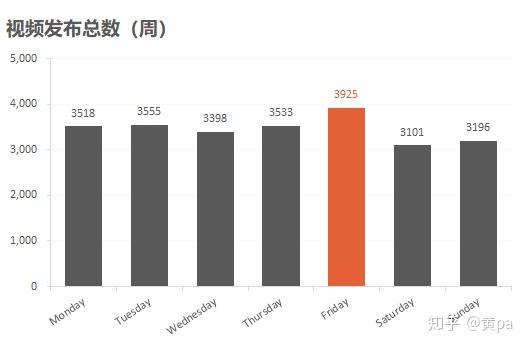
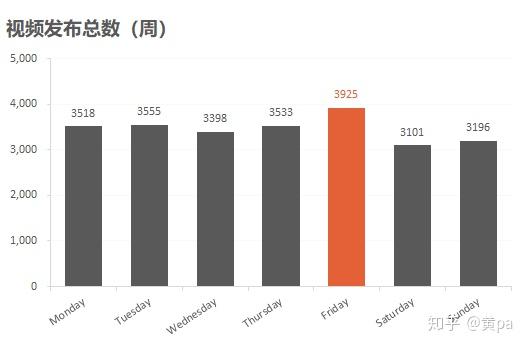
星期一至星期四的视频发布总数差值较小,星期五的值最大,周末两天是一周中最小的。可结合全网视频的发布时间,分析对应的总视频数,判断此规律是否只存在于热门视频。
(3)小时
通过数据透视表,行选择发布时间,值选择计数,再点击透视表中日期列,右键创建组合-步长选择时,即可得到小时的汇总数。
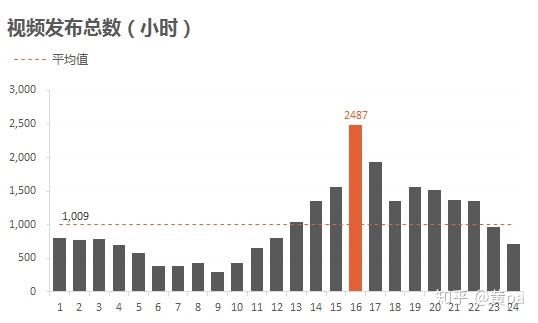
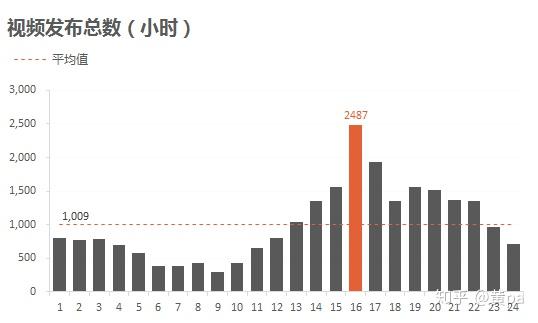
视频发布时间集中在13-22时,发布的视频数均超过了均值1009,其中16时最高,是均值的2倍多,而6-10时的视频数尤其低。可结合全网视频的发布时间,分析对应的总视频数,判断此规律是否只存在于热门视频。
5.分析结果与建议
- 总体而言,网站热门视频中Entertainment类视频的数量远大于其他类别,这也说明了市场的需求。而Music和Comedy的视频则明显更多地被多次推荐,产出热门视频中的超爆热度视频。
- 绝大部分的视频只被单次推荐,能达到最多推荐次数的是凤毛麟角。视频数随着推荐次数的递增而依次递减。首次推荐历时天数集中在0-4天,1天的视频数最高。发布4天后还未被推荐,则希望渺茫。而要成为推荐次数到达7、8次的王者,则必须在0或1天被首次推荐。
- 用户观看视频后更倾向于表达喜欢和评论,或许这就是热门视频的魅力。越受喜欢的视频也会有更多的评论,而不喜欢则倾向沉默。
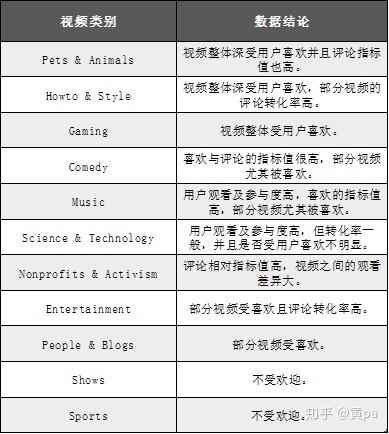
- 综合指标来说,Music最受大众欢迎;Pets&Animals最易获得喜爱;Howto&Style、Gaming、Comedy次之。当然还应该进一步结合全网视频的各类别视频的热门视频占比衡量。部分视频类别与参与度相关数据呈现了一定的特征,如下表。
- 标签数量不会对视频产生正面或负面的影响,适度添加关键性标签即可。
- 视频发布时间集中在11月-5月,而7-10月的视频数极低,只有个位数。一周中星期一至星期四的视频发布总数波动小,星期五到达高峰,而周末两天为低谷。一天中集中于13-22时,其中16时最高。还需结合全网视频发布时间对应的总视频数,分析此规律是否只存在于热门视频。