

最近,在海外马老板的推动下,Twitter开源了For You场景部分推荐算法源码。业务相关,先学习了一下rank相关的逻辑和实现,在此做个整理。
开源代码中,Ranking主要包括light-ranker和heavy-ranker两部分。
- light-ranker被推特的实时搜索系统Earlybird用于对推文排序,处于半废弃待升级迭代的状态。
- heavy-ranker用于For You场景下的精排。
下面主要介绍对这两部分的学习。
一、Earlybird light rank
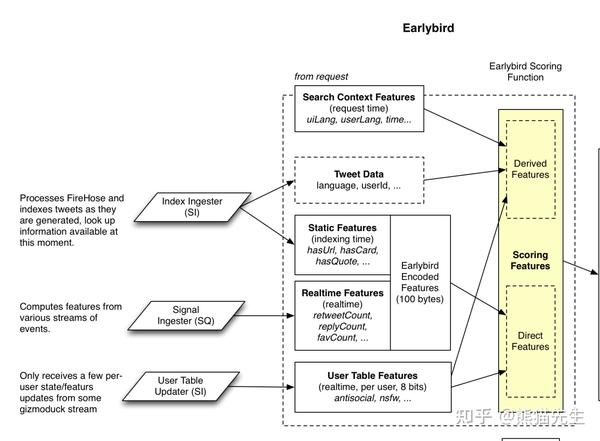
(一)、特征pipeline
Earlybird light rank模块所需的特征主要包括四部分
- Index Ingester 负责构建推文相关的基础特征和静态特征,如推文使用的语言、是否有url等。
- Signal Ingester 负责构建推文的动态/实时特征,如推文的喜欢数量、回复数量等;
- User Table Updater 负责构建每个用户的实时特征;
- Search Contet Features 负责构建用户请求当前的状态信息,如UI的语言、当前时间信息等。
上述静态特征+动态特征将会被模型用于评估用户与候选推文的互动概率。
(二)、模型训练
- 基于逻辑回归模型LR去预测用户与推文互动的概率
- 设计为多目标模型(is_clicked is_favorited is_replied is_retweet等)
- 使用深度学习框架twml(即将废弃)进行模型训练预测,目前线上有两种light rank,区别在于模型特征不同。
- in-network rank
特征详见src/python/twitter/deepbird/projects/timelines/configs/recap/feature_config.py
- out-of-network rank
特征详见 src/python/twitter/deepbird/projects/timelines/configs/rectweet_earlybird/feature_config.py
二、heavy rank
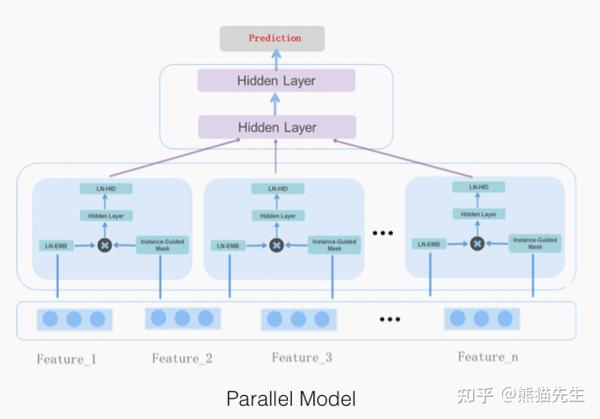
(一)、模型结构
heavy rank采用微博团队2021年提出的parallel MaskNet(个人猜测原因一方面是masknet属实牛逼,一方面是两个团队的场景较为相似,社交属性很强)。
(二)、源码阅读
参考 https://github.com/twitter/the-algorithm-ml 对heavy rank的主体逻辑做了简单梳理。
1、优化目标
基于“For You”场景,推特选取了10个待优化目标,分别是
- is_favorited: 用户喜欢推文的概率
- is_good_clicked_convo_desc_favorited_or_replied: 用户点击进推文并回复或喜欢的概率
- is_good_clicked_convo_desc_v2: 用户点击进推文后停留至少2分钟的概率
- is_negative_feedback_v2: 用户有负反馈行为的概率
- is_profile_clicked_and_profile_engaged: 用户进入到作者主页互动的概率
- is_replied: 用户回复推文的概率
- is_replied_reply_engaged_by_author: 用户回复的推文被作者回复的概率
- is_report_tweet_clicked: 用户举报推文的概率
- is_retweeted: 用户转发推文的概率
- is_video_playback_50: 对于包含视频的推文 用户观看时长超过50%的概率
目前配置文件local_prod.yaml中优化目标的权重pos_weight均为1,具体的权重值需要根据业务侧调整。
2、模型结构
create_ranking_model()函数给出了模型结构的实现,twitter基于MaskNet构建的多目标模型的总体结构如下图所示。
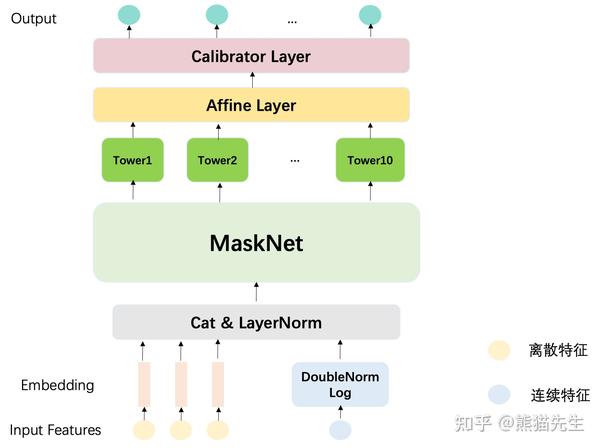
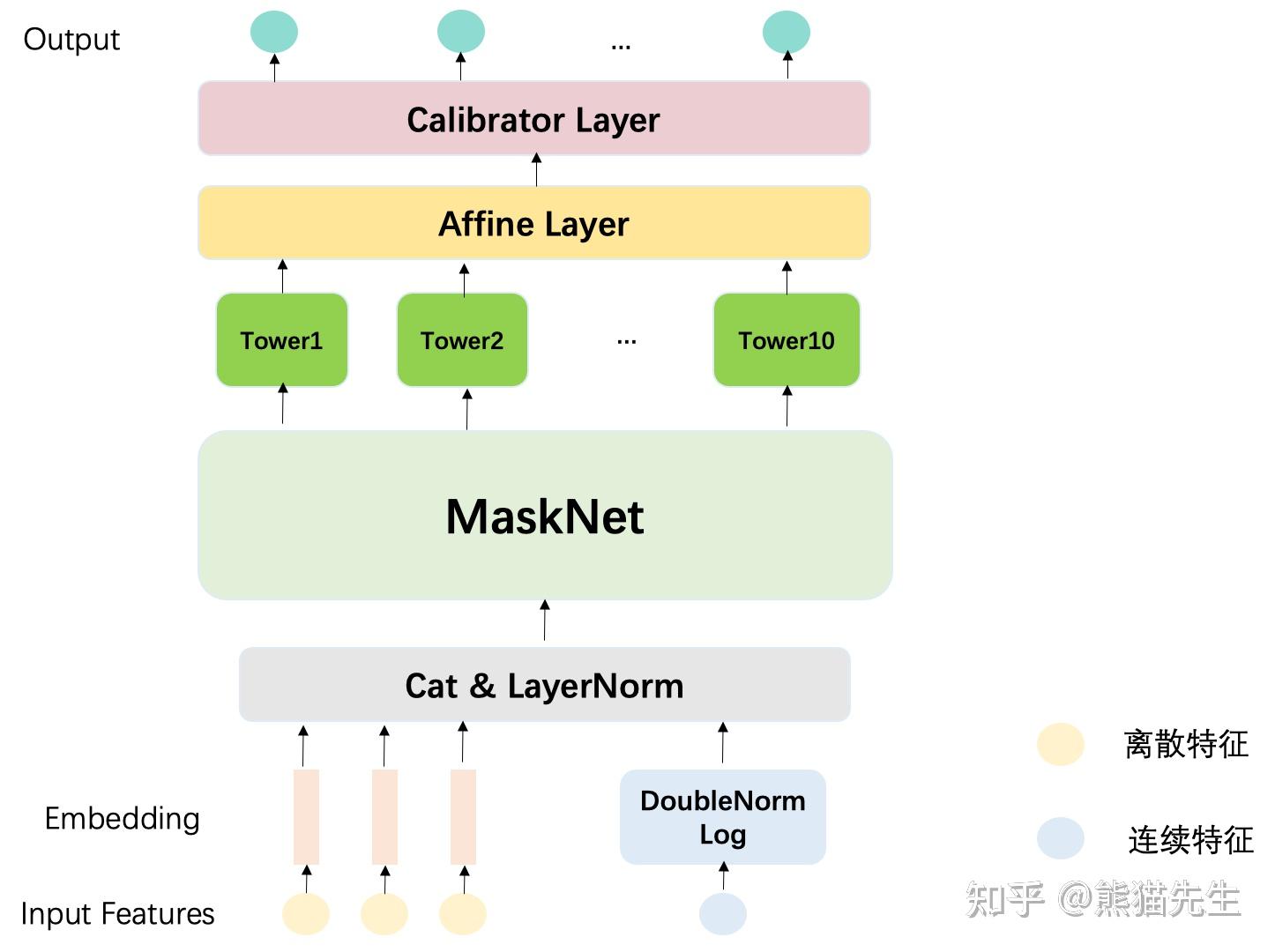
- 在对输入特征进行预处理后,模型以Parallel MaskNet作为backbone,上层接入N个Task Tower预测用户在特定任务下的正样本概率,最终输出校验后的概率值,采用交叉熵损失计算模型loss,更新模型参数。
- 特征预处理
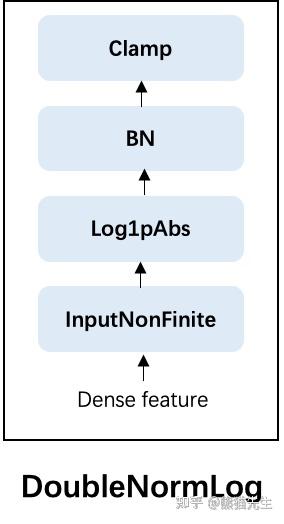
- 连续特征: 参考build_features_preprocessor()和DoubleNormLog()函数,对连续值,依次进行
- InputNonFinite: 替换输入中的nan、inf、-inf值,默认替换值为0
- Log1pAbs: 对连续特征进行log变换, 具体公式参考 f(x)=sign(x)\cdot log_{e}(1+|x|)
- BatchNorm(可选 配置文件决定)
- Clamp裁剪, 将输入的值域约束到[-clip_magnitude, clip_magnitude] (clip_magnitude由配置指定)
- 离散特征:
- Embed
将处理后的连续特征和离散特征cat到一起,并根据配置信息决定是否要进行LayerNorm。
- MaskBlock实现
参考配置文件local_prod.yaml和脚本mask_net.py。
MaskNet模型的关键在于MaskBlock模块,设计该模块的主要目的是 克服简单的MLP网络无法有效捕捉复杂交叉特征的局限性, 这一模块主要包含三个组成部分: LN、IGM(instance-guided mask)、feed-forward hidden layer。
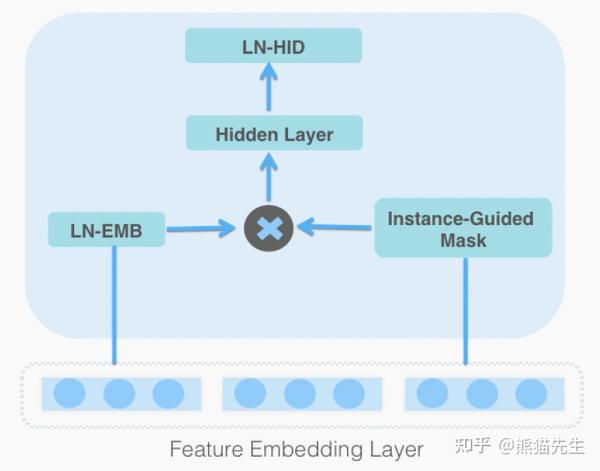
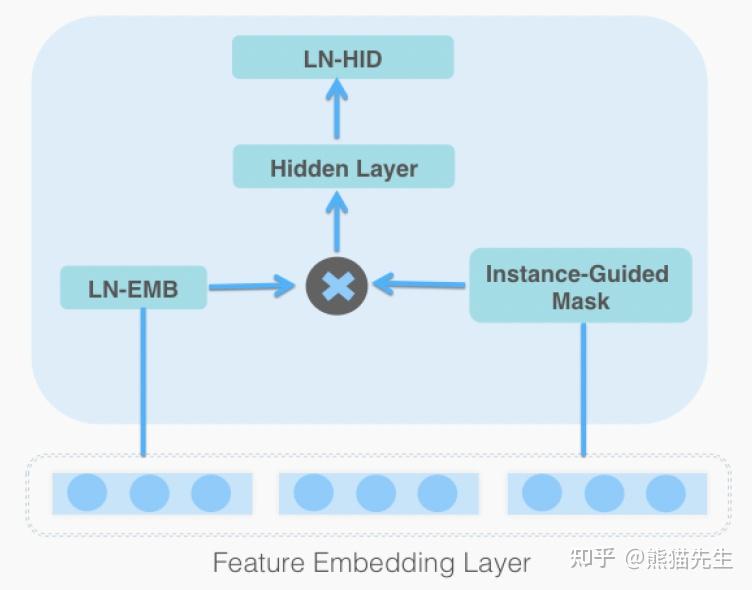
twitter给出的MaskBlock实现如下:
IGM本质上就是由负责aggregation和projection的两层FC实现,aggregation layer为了更好的从输入中获取全局信息,一般设计成宽网络,根据配置信息可以了解到twitter将这一层FC的输出神经元设置为1024。
- parallel masknet实现
论文中给出了MaskNet的两种实现方式: Parallel MaskNet 和 Serial MaskNet,显然parallel model训练和推理的速度更快,考虑到线上服务延迟(猜的),twitter选择Parallel MaskNet,即上图2。
需要注意的是,选择parallel 的实现方式的话,MaskBlock的两个输入必须都是 feature embedding。
twitter给出的MaskNet实现如下(同时实现了串行和并行方式,根据配置决定)。
- 多任务模型实现
以上述的MaskNet作为backbone,上层接入特定的task towers,就构建起推特的多任务模型。下面只给出关键步骤代码,完整代码可以参考 https://github.com/twitter/the-algorithm-ml/blob/main/projects/home/recap/model/entrypoint.py
上述就是heavy-rank的主体逻辑和实现,之后的模型训练流程大同小异。
这就是本文的主要内容,后续会对开源的其他模块代码再做梳理。文中若有误,烦请评论区指正。
ps: 开源原因未做过多揣测,猜测可能的原因包括但不限于
- 提升平台透明度,让用户用的放心,且开源后可以获取更多用户反馈。
- 各大厂推荐算法在大流程上一致性较强,都是召回-粗排-精排-重排几个关键模块,开源代码仅是给出了推特在这些大模块上的算法实现,是推特For You真实系统的一个主干逻辑,主干逻辑 + 旁枝末节上的算法 + 业务上的策略调整才决定了最终的下发内容。