

背景
3月31日,Twitter如期开源了推荐算法,作为行业的头部公司,Twitter在推荐领域的实践具有较高的学习价值。本篇是系列学习笔记的第二篇,关注Twitter的排序算法模型。
随着深度网络模型在自然语言处理、图像处理和推荐系统领域的发展和应用,特征建模也成为重点关注的研究方向。在一些推荐场景,用户的交互集中在头部item,行为特征分布极为不均。特征的稀疏特性,为建模工作带来了一定挑战,如何从高维稀疏的特征向量提取有效特征,也是特征工程中值得探究的方向。
本文介绍了Twitter使用的MaskNet网络模型,通过类似门控机制的方式对输入原始特征进行特征选择,然后再输入到下层网络进行训练。该网络是新浪微博在探索特征建模工作中的一个重要成果,最初在2021年发布了相关论文,并在公开的Criteo、Malware和Avazu CTR任务中取得显著成果。通过Twitter的开源代码,我们可以了解到Twitter在工程实践中如何对模型修改适配,也能观察到一些有趣的技术细节。
MaskNet网络
MaskNet[1]网络旨在解决Click-Through Rate(CTR) 预估任务,它是通过预测用户发生点击推文的概率,为推文进行打分排序。
目前,主流CTR(点击率)预估模型都遵循"Embedding&MLP"结构设计,其中,MLP(多层感知器,一种前馈神经网络)负责进行特征交叉,提升模型的泛化能力,但一些研究证明简单的MLP结构是无法有效学习复杂特征交叉的。因此,如何有效捕捉复杂的高阶特征至关重要。MaskNet 模型正是将门控机制[2]作用于MLP中,动态学习各特征重要度,进而提高特征交叉效率和模型效果。
我们先来了解一下排序算法的网络结构,MaskNet主要由两种实现方式: Serial Model(串行结构)和Parallel Model(并行结构),两种实现的共同点在于均由多个MaskBlock组成,下面分别介绍具体实现方式:
Serial MaskNet
如图1所示为串行结构的实现,其结构与RNN类似,具备如下特点:
- 第一个MaskBlock为MaskBlock on Feature Embedding,输入均为特征Embedding。
- 其余的Maskblock均为 MaskBlock on MaskBlock,输入均为[前一个Maskblock输出、特征Embedding]。
显然,串行方式的训练、推理耗时更久。
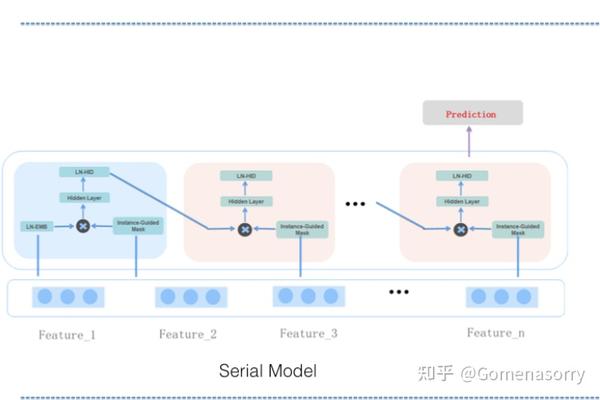
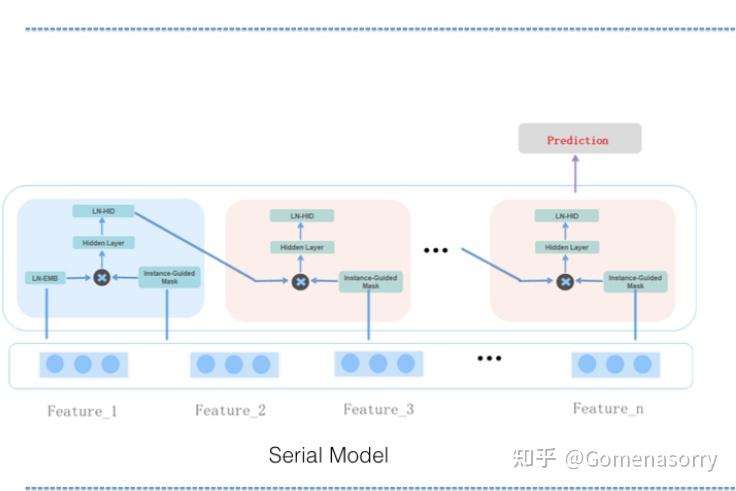
图1 串行结构
Parallel MaskNet
如图2所示为MaskNet并行结构的实现,具备如下特点:
- 所有的MaskBlock均为 MaskBlock on Feature Embedding,输入均为特征Embedding。
- 多个MaskBlock层结果拼接,堆叠MLP结构,用于进一步处理学习到的交叉特征。
此结构类似于MMOE[3](多任务学习模型),每个MaskBlock聚焦于学习不同的交叉特征;相比于串行结构,具备训练、推理耗时短的优点。
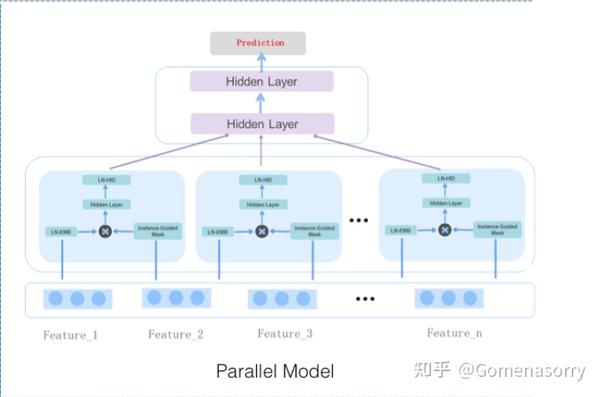
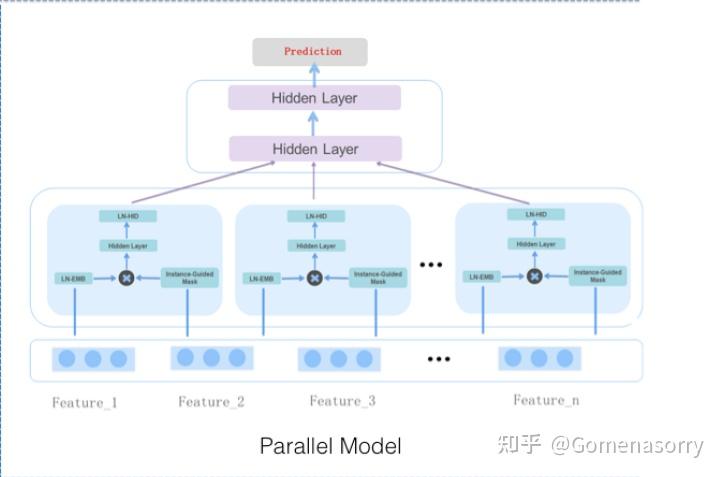
图2 并行结构
最终都需经过Prediction Layer(神经网络中层)将前面的特征表示转换为最终的预测结果。
MaskNet模型的核心在于MaskBlock的网络设计,这是该算法有效捕获特征信息的关键。
MaskBlock介绍
设计MaskBlock模块的主要目的是克服简单的MLP网络无法有效捕捉复杂交叉特征的局限性, 在这里也使用到了关键的attention机制[4],该模块主要包含三个组成部分: LayerNorm(层归一化)、instance-guided mask、feed-forward hidden layer(前馈隐藏层,获取重要的特征交互)。分别形成MaskBlock on Feature Embedding结构和MaskBlock on MaskBlock结构。
MaskBlock on Feature Embedding
对特征Embedding进行类门控机制操作,具体结构如图3所示,流程如下:
- 对特征Embedding进行LayerNorm操作,可以简化模型的优化过程,生成LN-EMB;
- 将特征Embedding输入给instance-guided mask模块,提取出特征相关的上下文信息,并以Hadamard Product[5](哈达玛积 )的形式与LN-EMB进行拼接;
- 利用Hidden Layer(前馈隐藏层)和LN-HID(LayerNorm+ReLU)聚合信息,便于更好的获取交叉特征。
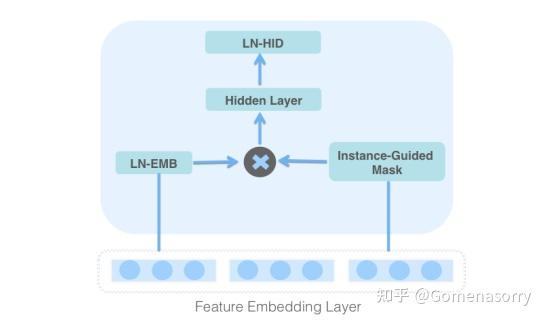
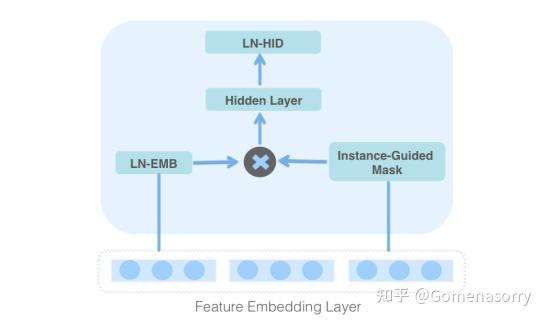
图3 MaskBlock on feature embedding
MaskBlock on MaskBlock
针对MLP结构应用特征类门控机制,实现图4所示的MaskBlock结构,具体流程如下:
- 获取前一个MaskBlock的输出Embedding。
- 将特征Embedding输入给instance-guided mask模块,提取出特征相关的上下文信息,并以Hadamard Product(哈达玛积 )的形式与上一个MaskBlock的输出Embedding进行拼接;
- 利用Hidden Layer(前馈隐藏层)和LN-HID(LayerNorm+ReLU)聚合信息,便于更好的获取交叉特征。
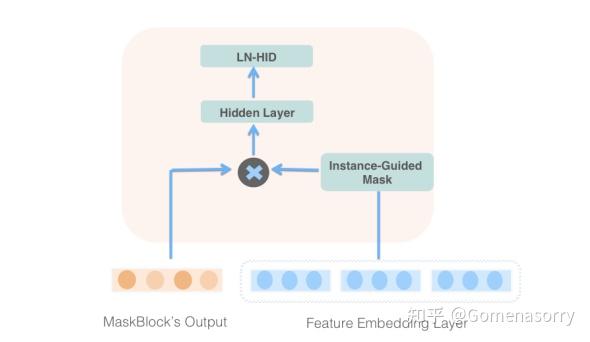
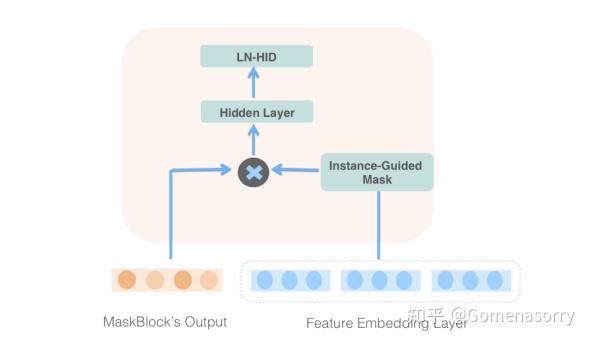
图4 MaskBlock on MaskBlock
MaskBlock核心是instance-guided mask模块,详解请看下章介绍。
Embedding Layer
特征嵌入层是(Feature Embedding Layer)MaskBlock网络的输入,是通过矩阵乘运算对稀疏特征的初筛,下面以示例的形式说明特征初筛的过程:
当前样本有两个特征域,用户购买的订购编码,用户浏览的订购编码,商品库中订购编码有10个,样本1:用户1购买了订购编码C,one-hot向量为[0,0,1,0,0,0,0,0,0,0],用户1浏览了订购编码C和D,one-hot向量为[0,0,1,1,0,0,0,0,0,0],one-hot特征维度为10,若是想每个特征域只留下k维,则通过下述运算进行特征选择:
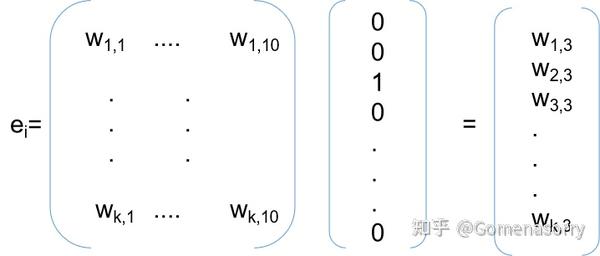
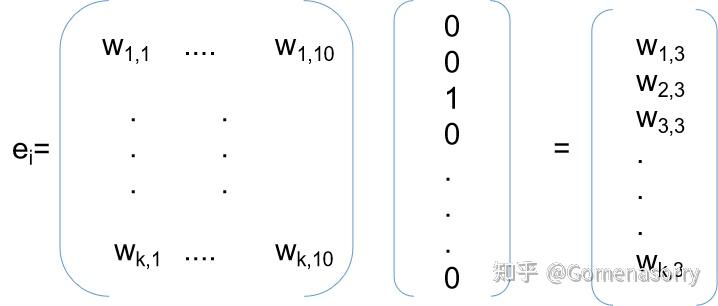
并将加权降维的两个特征域拼接得到长度为k*2的Vemb,Vemb即维MaskBlock网络的输入。
Instance-Guided Mask
由两层全连接网络(FC)构成,全连接层的每个节点都与上层的所有结点链接,可以充分捕捉上下文信息。计算分为两步:
- Aggregation Layer(聚合层): 设计为宽网络(FC输出的神经元数量相对更大),目的是提升学习能力,可以聚合上下文信息。
- Projection Layer(映射层): 设计为窄网络(FC神经元数量与Vemb的维度保持一致),将聚合的上下文信息张量映射到特征Vemb空间。
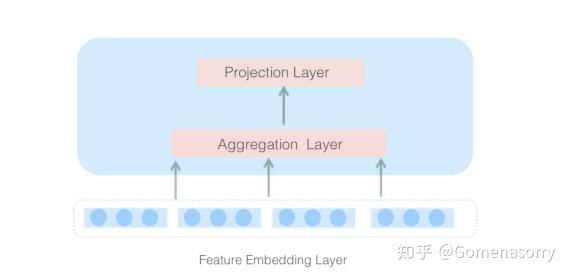
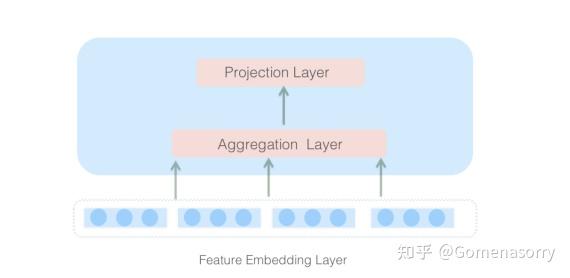
图5 Neural Structure of Instance-Guided Mask
Layer Normalization
Layer Normalization[5](层归一化)是一种在神经网络中应用的归一化技术,是通过对每一个样本的所有特征进行归一化,将数据的特征值映射到符合标准正态分布,具体实现原理如下图所示。
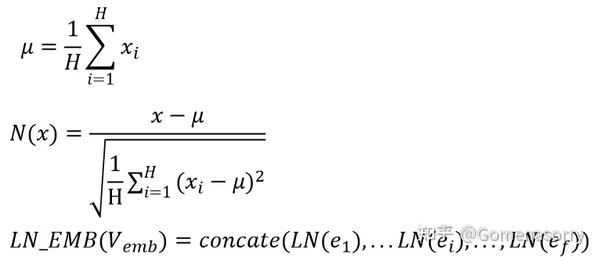
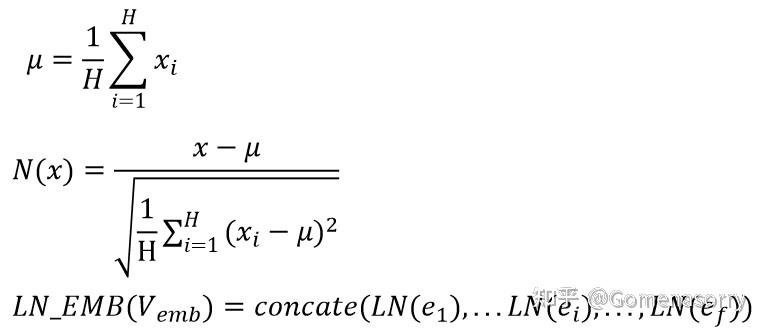
Layer Normalization具有以下优势:
- 更强的泛化能力:由于Batch Normalization的计算是在训练数据上进行的,因此它可能对新的、未见过的数据存在泛化能力的问题。而Layer Normalization是对每个样本进行归一化,因此可以更好地适应不同的数据分布,从而具有更强的泛化能力。
- 更少的内存占用:Batch Normalization需要存储每个特征维度的均值和方差,因此在内存占用方面可能存在一定的问题。而Layer Normalization只需要存储每个特征维度的均值和方差,因此占用的内存更少。
MaskNet排序在推特算法中的运用
介绍
排序模块运用了MaskNet排序算法的思想。排序(Heavy Ranker) 在推特的For you这个组件中扮演的角色是为用户推荐更加相关的推文,首先将每天约5 亿条的推文过滤到1500条左右,再对这些候选推文打分排序。推特在实际应用中通过对点击、转发、收藏、浏览时长等多个目标进行学习建模,在线服务的时候,模型为每条推文输出了在10个指标上的预测概率,最终由一个模型将行为概率进行加权融合,推文最终的排序顺序实际上是根据10个业务指标加权得出的综合平均分来确定。
排序模块整体架构
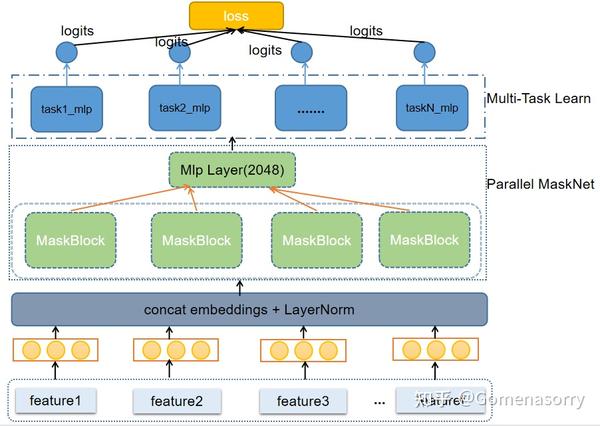
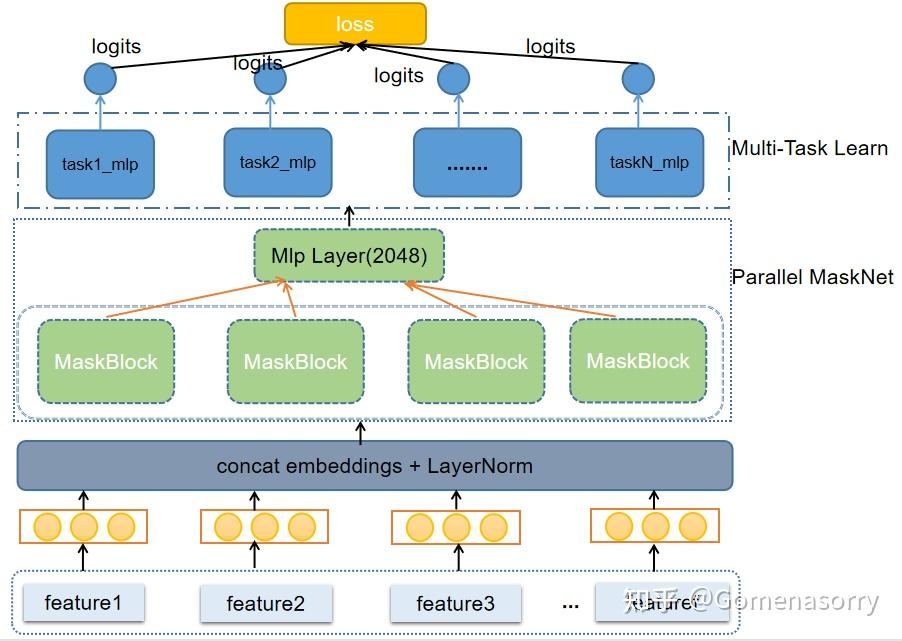
Parallel MaskNet
推特在实践中选择了并行的MaskNet网络,使用了4个MaskBlock,通过对特征进行转换,强化更加有价值的特征信号,同时弱化无效特征的噪声信号。在这里笔者猜测,推特没有选择串行网络(Serial MaskNet),而是使用并行网络(Parallel MaskNet)的原因如下:
- 并行的maskNet能够同时产出4个maskBlock输出,在特征表达上更加丰富
- 能够更快的训练,提升模型的更新频率。推理预测时也会更省时间,服务会有更快的响应速度。
多任务网络
- 每个任务是一个(256x128x1)三层网络,每个任务根据自己要学习的目标调整网络权重,最终各个任务都能"独当一面"
- 多任务网络,较一个任务一个网络而言整体的架构模型参数更少,训练也更快。它共享Parallel Model网络层权重,多个任务的数据一起来学习,学习的效果有可能要比每个任务单独学习的结果要好,笔者猜测是通过多个任务的共享信息来提高在所有任务上的泛化性
- Parallel MaskNet 和 多任务网络的模型参数初始化均使用的是xavier_uniform
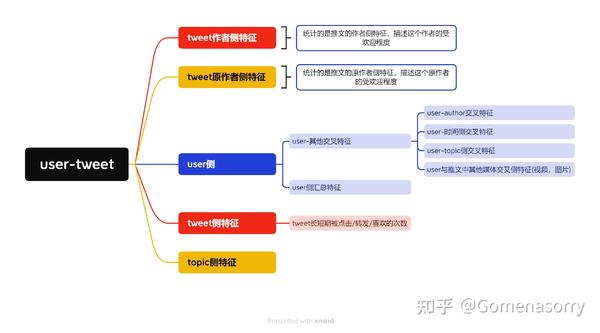
特征工程
特征名称格式
| Feature Group Name | Engagement Scope | Feature To Aggregate | Aggregation Spec |
| 圈定要描述的对象范围 | 圈定要描述的tweets范围 | 统计指定范围内具体的特征 | 特征的计算方法及时间窗口 |
举个例子
user_aggregate_v2.pair.recap.engagement.is_favorited.any_feature.50.days.count
| user_aggregate_v2.pair | recap.engagement.is_favorited | engagement_features.in_network.replies.count | 50.days.count |
特征的含义是:以用户喜欢的推特为分组,统计用户在网络上回复的次数。其中统计周期是50天,函数是统计次数。
推特使用的特征
以聚合特征为例,Twitter使用聚合特征作为排序特征的一部分,以帮助决定哪些推文应该在用户的时间线上显示。聚合特征是指在一定时间范围内,将某些指标值(如点赞数、转发数、评论数等)聚合计算后得到的结果。具体见下图。
Twitter的聚合特征分为长期聚合和短期聚合两种。长期聚合是在50天的时间窗口内对特定范围内的指标值进行计算,以获取相对稳定的趋势和数据。而短期聚合则是针对“实时”数据进行计算,通常在3天以内或者30分钟内完成计算。这样可以更快地响应当前的话题和热点,并及时更新排序特征。Twitter的聚合特征是由大量数据和机器学习算法共同构建而成的。通过对用户行为和推文内容进行分析,Twitter可以根据用户的兴趣和偏好,为用户提供更加个性化的时间线推荐。
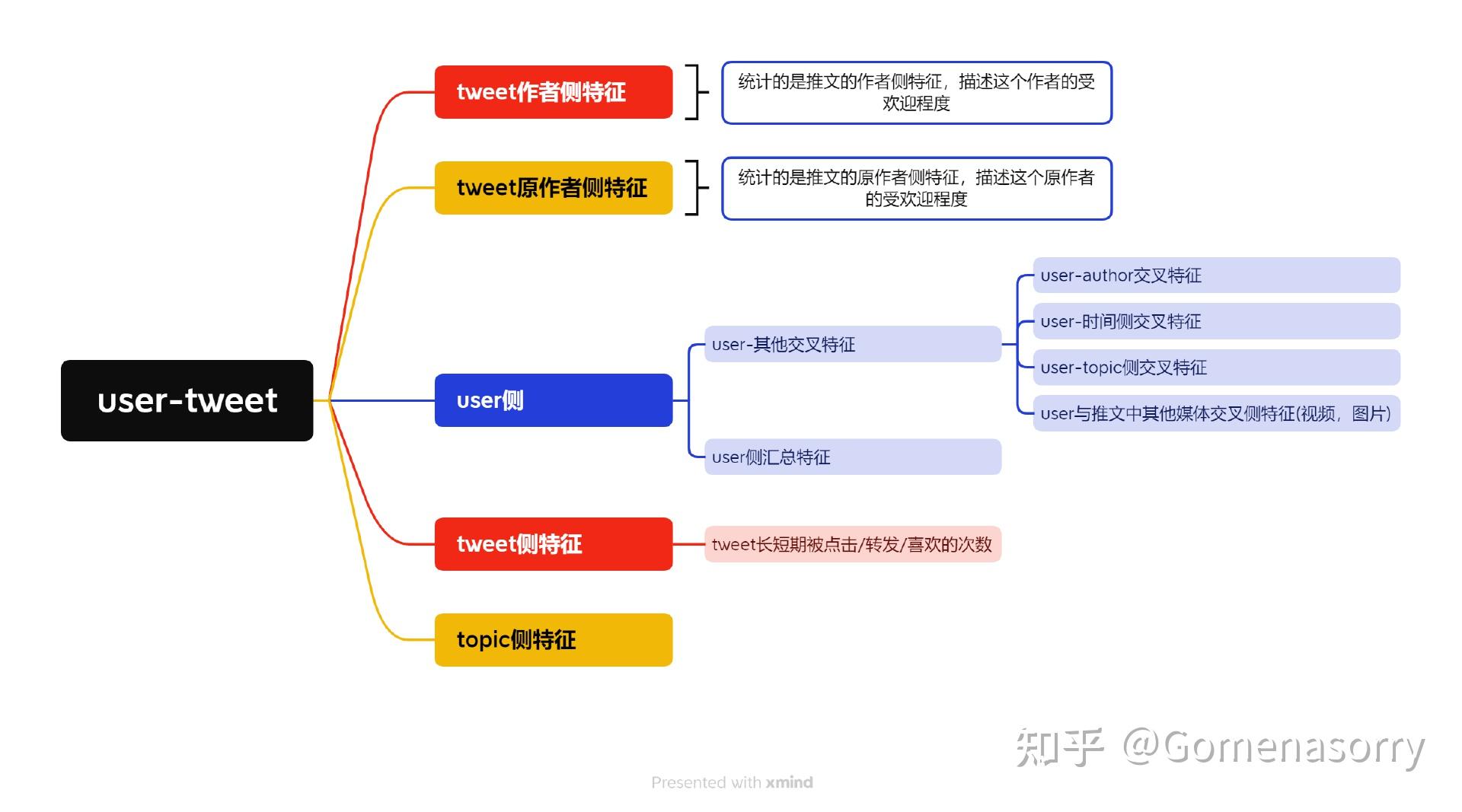
排序目标
推特排序核心使用的是一个并行 MaskNet架构。如上图所示,每个task的目标就是预测对应用户行为(engagement )的概率。在计算排序打分的时候,不同的行为具有不同的权重。当行为权重为负数,说明该行为将会降低最终得分,反之则相反。例如is_negative_feedback_v2等于-74,在其他条件相同情况下,计算最终加权得分时,则应该给它更靠后的排序位置。推特排序模块的task有10个,对应的是预测10种行为发生的概率,具体如下:
| 行为(engagement ) | 行为权重(weight of engagement) | 解释(explain) |
| is_favorited是否收藏 | 0.5 | The probability the user will favorite the Tweet用户收藏推特的概率 |
| is_good_clicked_convo_desc_favorited_or_replied是否点击推文并回复或点赞 | 11 | The probability the user will click into the conversation of this Tweet and reply or Like a Tweet. 用户点进推特详情,点赞或回复了推文的概率 |
| is_good_clicked_convo_desc_v2是否点击推文并停留2分钟 | 10 | The probability the user will click into the conversation of this Tweet and stay there for at least 2 minutes. 用户点进推特详情,停留超过2分钟的概率 |
| is_negative_feedback_v2是否负反馈 | -74 | The probability the user will react negatively用户负向互动的概率 |
| is_profile_clicked_and_profile_engaged是否点击作者档案并互动 | 12.0 | The probability the user opens the Tweet author profile and Likes or replies to a Tweet. 用户点开作者简介并点赞或回复了推特 |
| is_replied是否回复 | 13.5 | The probability the user replies to the Tweet. 用户回复推文的概率 |
| is_replied_reply_engaged_by_author是否回复推文并被作者互动 | 75.0 | The probability the user replies to the Tweet and this reply is engaged by the Tweet author. 用户回复推文并且被推文作者互动的概率 |
| is_report_tweet_clicked是否点击举报按钮 | -369 | The probability the user will click Report Tweet 用户点击举报按钮的概率 |
| is_retweeted是否转发推文 | 1 | The probability the user will Retweet the Tweet 用户转发推文的概率 |
| is_video_playback_50视频推文播放进度是否超过一半 | 0.005 | The probability (for a video Tweet) that the user will watch at least half of the video. 用户观看推文视频进度至少过半的概率 |
对于每个用户,它输出一组 0 到 1 之间的数字,每个输出代表用户与推文发生不同行为的概率。例如点击概率,分享概率等10中行为。具体示例如下:
| user | Tweet | is_favorited | is_retweeted | .... | is_replied | is_report_tweet_clicked |
| user | tweet | 0.8 | 0.7 | 0.8 | 0.6 |
目标函数
推特算法使用的是BCEWithLogitsLoss。对于每个样本,每个task都输出的是一个0-1的概率值。计算损失的时候对于正样本权重为1,每一轮训练的最终损失为所有样本对应损失的均值。具体计算原理入下图所示。


示例
把问题简化为一个用户有对tweet发生3种行为,预测每个行为的概率,并利用BCEWithLogitsLoss原理计算损失,最后求平均。具体示例:
| 用户真实行为 | 模型预测用户不同行为的概率 | ||||||||
| is_favorited | is_retweeted | is_replied | is_favorited | is_retweeted | is_replied | Loss | mean(Loss) | ||
| user_0 | tweet_0 | 1 | 0 | 1 | 0.8 | 0.7 | 0.8 | 0.6151 | 0.6620 |
| user_1 | tweet_1 | 0 | 1 | 1 | 0.5 | 0.3 | 0.2 | 0.7089 |
总结与下一步工作
该模型主要目的在于提炼捕获用户在行为序列中呈现出的特征,通过某种自注意力机制,做到对不同用户针对性地放大不同行为模式的信号。在具体实践中应用时,是否能够通过不同用户的行为序列特征是否具备充分的差异性,是需要讨论和验证的。Twitter的社交网络场景下有足够丰富的行为类型,阅读、点赞、转发、收藏、评论、转发加评论、评论后收藏……,有些用户喜欢收藏不转发,有些用户喜欢转发加评论,所以可以从中识别出一些模式,而在非SNS的业务场景,可能并不存在如此多样的行为,如果要尝试使用同样的算法,那么在使用网络构建embedding时就需要考虑引入更多的用户行为数据。
不过推特的实践仍然非常具有参考价值,有很多地方都值得引入到实际业务中验证,笔者在此提出这些:
- Twitter在原论文的基础上,实践时应用了多目标学习的方式,通过构建多个专家网络来专注不同的目标,训练时可以认为所有任务同等重要,在线上serving时则对不同目标进行加权调整,这种方法可以快速地响应运营层面的诉求,而不需要重新训练模型。
- 采用并行的特征网络架构则是采取了一种用空间换时间的思路,同结构网络的冗余设计,笔者认为这类似一种赛马机制,也许最终起决定性作用的只是其中一两个MaskBlock,但是却可以在较短的时间获得较好的性能。
- 在非SNS场景中,虽然用户行为类型不够多样,但是也可以尝试基于已有行为的特征,引入Attention机制,对不同用户的行为模式进行增强。
引用
1.Zhiqiang Wang, Qingyun She, Junlin Zhang.MaskNet: Introducing Feature-Wise Multiplication to CTR Ranking Models by Instance-Guided Mask.
2.Albert Gu, Caglar Gulcehre, Tom Le Paine, Matt Hoffman, Razvan Pascanu. Improving the Gating Mechanism of Recurrent Neural Networks.
3.Jiaqi Ma,Zhe Zhao,Xinyang Yi,Jilin Chen,Lichan Hong,Ed H. Chi. Modeling Task Relationships in Multi-task Learning with Multi-gate Mixture-of-Experts.
4.Jun Xiao, Hao Ye, Xiangnan He, Hanwang Zhang, Fei Wu, and Tat-Seng Chua.
2017. Attentional factorization machines: Learning the weight of feature interac
tions via attention networks. arXiv preprint arXiv:1708.04617 (2017).
5.JH Kim,BT Zhang,KW On,J Kim,JW Ha.Hadamard Product for Low-rank Bilinear Pooling.
6.Jimmy Lei Ba,Jamie Ryan Kiros,Geoffrey E. Hinton.Layer Normalization.