

今天为大家介绍的是来自Abeed Sarker研究团队的一篇发表在PNAS上的关于非医学药物滥用的人口统计的论文。通过社交媒体进行非医学物质使用监测具有提供低成本和更及时见解的潜力,比传统方法更有优势。然而,目前基于社交媒体的方法缺乏提供精细的亚人群级别统计数据的能力。作者团队试图填补这一空白,通过开发自然语言处理方法来估计在Twitter上报告非医学处方药使用的大型队列(N = 288,562)的人口分布(性别,年龄和种族)。自动导出的阿片类药物,兴奋剂和镇定剂的分布与传统来源(如国家药物使用和健康调查)报告的统计数据大体上一致,具有非常强的相关性。作者团队的工作代表了在确立社交媒体作为补充药物使用监测方面迈出的重要一步。


传统的药物滥用(substance use,SU)监测方法会产生相当大的滞后。由于SU趋势不断演变,通过这种方法获得的数据分析结果往往已经过时。目前已有利用社交媒体进行监测来获得及时数据分析的工作,但是这种数据利用方法通常不能提供关于亚种群的精细统计数据,而这是传统方法的优势之一。作者通过开发自然语言处理和机器学习方法来自动化对大型推特非医疗处方药物使用(NPMU)群体(n = 288,562)进行特征化,从而填补了这一差距。在美国,长期以来,吸毒、药物滥用等物质使用问题一直是一个重大的公共卫生问题。不论采取了多少预防措施,由于药物滥用导致的过量死亡数量仍在稳步上升。2020年,SU相关的过量死亡率比2019年增长了31%,达到每10万人口28.3人,相比1980年记录的死亡率增长了20多倍。预估在2022年3月之前的12个月内,将有超过100,000人死于物质使用相关的问题,这是有记录以来最高的12个月死亡人数。
此外,与药物使用障碍(SU disorder, SUD)及其相关健康影响有关的不平等问题也非常严重。许多最近的研究已经强调了与社会经济地位、种族/族裔、性别认同/生物性别、社区、犯罪记录和医疗保险覆盖范围相关的不平等问题。例如,研究表明,非白人(非裔美国人和西班牙裔人)使用缓解药物的可能性较低,而女性使用缓解药物的可能性也较低。此外,非白人(非裔美国人和美洲印第安人以及阿拉斯加原住民)在2019年和2020年的药物过量死亡率中增长最快,而非裔美国人使用兴奋剂和阿片类药物导致的死亡率增长要高得多。据报道,收入较低、居住在非大城市地区或没有医疗保险的人更容易患上SUD。多种不平等现象可能同时存在,加剧物质使用和滥用的可能性。因此,非白人(非裔美国人、西班牙裔/拉丁裔、美洲印第安人和夏威夷土生土长的其他太平洋岛屿人)也面临着严重的SUD不平等问题,而不同的人口群体可能因其独特的文化、历史背景和规范而面临着针对性监测和应对的挑战。
有效应对药物过量死亡危机和减轻不平等的重要方法是改善监测机制,特别是加快数据整理过程,以提供及时、准确、可操作的洞见。传统监测方法和/或数据来源包括调查,例如由国家药物使用和健康调查(NSDUH)进行的调查、毒物控制中心、有关治疗入院和出院的医院数据、与过量有关的急诊科访问(EDV)以及过量死亡记录。这些传统监测系统与数据收集、整理和发布的周期有相当大的滞后期。例如,2020年NSDUH年度全国报告直到2021年10月底才发布。由于这种滞后,物质使用/过量的趋势只能在事后被检测和理解,通常是在已经造成了相当大的损害和/或物质使用模式已经发生变化之后。由于物质使用/过量危机多年来一直在不断发展,这种滞后尤其成为问题。例如,在2000年代初期(美国),导致过量死亡的主要原因是可卡因,后来被处方阿片类药物取代,随后是海洛因。而近年来,合成阿片类药物(例如芬太尼)和精神刺激剂(例如甲基苯丙胺)的死亡人数有明显增加。依靠传统的监测方法意味着要等数月后才能知道流行病的当前确切轨迹。因此,迫切需要准确的、接近实时的物质使用监测系统。
为了弥补传统方法的不足,社交媒体被提出作为即时监测的潜在补充资源。超过2.2亿美国人(约70%的人口)使用社交媒体,并讨论许多与健康相关的话题,包括自我报告的药物使用/药物使用障碍。理论上,这些公开可用的讨论可以使用自然语言处理(NLP)方法进行近乎实时的挖掘。然而,由于数据的各种特征,如口语表达、拼写错误和噪声等,对健康相关聊天内容进行NLP是困难的。在社交媒体的物质使用/物质使用障碍研究领域,研究人员在过去十年中不断发展和应用越来越复杂的方法。早期的研究尝试利用在线健康社区的数据,这些社区有专门的论坛用于讨论非医学使用(NMU)。依靠有专门论坛的在线健康社区可以确保研究者有丰富的数据可用,虽然信息量可能较低,因为这些社区的订阅者数量不是很多。利用Twitter等通用社交网络的数据的研究最初主要关注基于特定物质讨论量的场景。一些研究者利用社交媒体中的元数据,例如Twitter上的帖子,获取有关地理位置的信息来获得洞察力。但是,基于其他人口特征的观察方式还尚未实现。这限制了使用此类数据进行细粒度、亚人群特定研究的能力,这与传统资源相比是一个明显的劣势。理想情况下,监测药物使用的数据需要覆盖全面的人口统计学范围(例如种族、年龄、性别和地理区域),并具有足够的细粒度来观察不同人口群体之间的微妙差异。准确自动估算社交媒体订阅人群的关键人口特征分布的方法可以实现精细的亚人群级别分析和比较,这是作者文中试图解决的问题。
数据源
作者收集了提到处方药的推文,并使用监督分类系统检测到了自我报告的非医疗处方药物使用,收集了从2018年3月6日到2021年4月30日的帖子。系统检测到482,902条指示非医疗处方药物使用的推文,并提取了其作者的元数据,包括如果有的话,他们的过去帖子历史。通过这种方式,作者收集了发布了指示非医疗处方药物使用的推文的288,562个Twitter订阅者的元数据和他们的过去帖子(超过10亿条推文)。我们将这个基于队列的数据集称为Twitter NPMU。
性别、年龄和种族分布
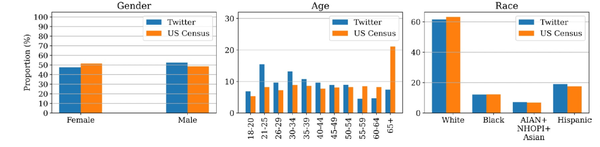
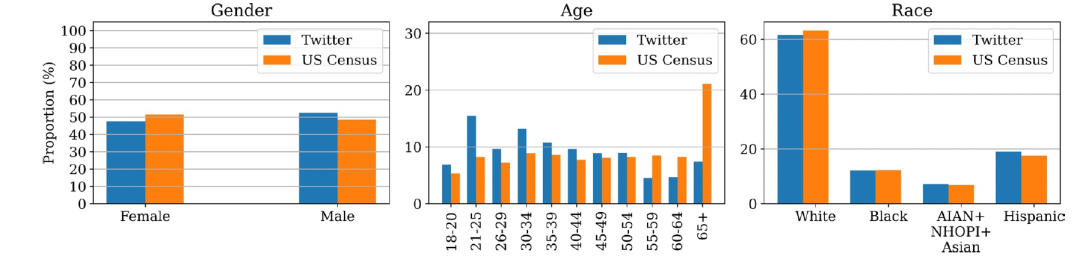
根据皮尤研究中心在2018年进行的Twitter调查和美国人口普查数据,推算出的Twitter订阅者的性别、年龄和种族比例如图1所示。从两个数据源得出的性别和种族比例相当,而年龄比例差异较大。与美国人口普查数据相比,Twitter上女性比例略低(少4%),白人比例略低(少1.5%),而西班牙裔比例略高(多1.5%)。两个数据源得出的比例接近表明,基于Twitter的性别和种族估计可能代表美国人口的分布情况。然而,在年龄方面,Twitter上有超过普查估计的年轻人,具体而言,在18至25岁群体中的人数比例约高出10%,而55岁及以上群体的比例则比普查估计低20%。年轻人在Twitter和社交媒体上的过度代表是一个众所周知的现象。在NPMU方面,从Twitter自动估计出的分布情况与NSDUH和NEDS的统计数据大部分相符。
性别分布估计
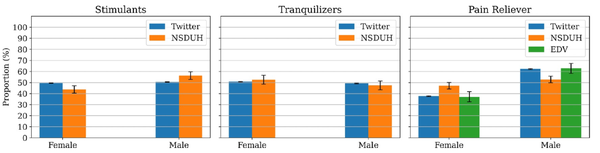
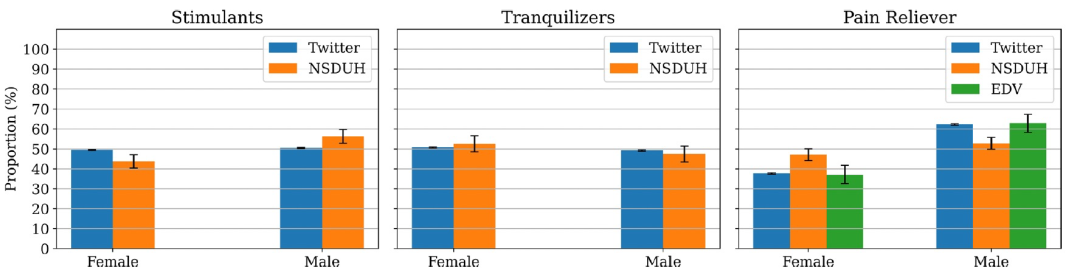
Twitter数据中的性别比例估计和传统来源,包括NSDUH和NEDS的性别比例分布如图2所示。包括镇定剂、兴奋剂和阿片类止痛药在内的三类药物的非医疗用药的性别比例。对于安定剂的非医疗用药,估计的Twitter比例在NSDUH报告的比例的95%置信区间内。对于兴奋剂,Twitter估计的女性比例略高于NSDUH报告的数字(约5%)。对于阿片类药物,Twitter估计的比例与NSDUH相比有显著差异(约10%)。具体而言,在Twitter上女性的比例低于NSDUH的估计值。有趣的是,作者发现,NSDUH报告的数字在阿片类药物相关的急诊访问病例中的比例分布也不同,但后者的估计值非常接近Twitter的比例。这表明,从Twitter中得出的估计值可能更能反映与过量相关的事件,而不是这一类别的非医疗用药。由于N很小,无法确定Twitter和NSDUH之间的相关性的统计显著性(Spearman r:0.66;P = 0.27)。
种族分布估计
这部分研究通过分析推特数据和传统数据来源中的种族比例,探究不同人群中的药物非医学使用情况,结果见图3。结果表明,推特数据和NSDUH(National Survey on Drug Use and Health)数据的种族比例分布相似,而推特数据中各种族比例均在NSDUH报告的对应比例的95%置信区间内或非常接近。对于所有药物类别,报告非医学使用的大多数人是白人,其次是拉丁裔和非裔。亚洲人的比例只占到了研究人群的4%或更少;AIAN(美国印第安人/阿拉斯加原住民)和NHOPI(夏威夷/太平洋岛屿原住民)群体的比例都不到1%。但值得注意的是,推特数据涵盖了所有少数族裔群体的数据。推特数据和NSDUH数据在白人和拉丁裔刺激剂组以及所有药物类别中的黑人方面存在较大差异(推特估计比NSDUH高)。总体而言,推特数据的种族比例分布与NSDUH的统计数据高度相关。
年龄分布估计
Twitter数据估计的年龄组比例和NSDUH的比例如图4所示。对于大多数年龄组,Twitter和NSDUH的估计值相似,总体相关性很强(Spearman r:0.673;P < 0.005)。最显著的差异是在年轻成年人(18至20和21至25岁)和老年人(65+岁)之间。Twitter估计的比例在18至20岁群体中一贯较低,而在21至25岁群体中较高。对于65+岁群体,与NSDUH相比,Twitter估计的比例在兴奋剂方面较高,在安定剂方面类似,在镇痛剂方面较低。对于阿片类镇痛剂,Twitter估计的21至25岁群体比例约高10%,65+岁群体比例约低6%。对于安定剂,Twitter估计的18至20岁群体比例约低6%,但65+岁群体比例没有显著差异。对于兴奋剂,Twitter估计的18至20岁群体比例约低10%,65+岁群体比例约高6%。
结论
作者利用自然语言处理技术,分析社交媒体平台Twitter上的自报非医疗药物使用(NPMU)言论,自动估计用户的人口统计特征,如性别、年龄、种族等,与传统数据源(如美国国家调查研究所(NSDUH)和国家紧急医疗服务部门(NEDS))进行比较。结果表明,Twitter上估计得到的大多数特征分布与传统数据源报告的结果一致,尤其是性别和种族分布。年龄分布方面,Twitter上估计得到的年轻人(18至20岁和21至25岁)和老年人(65岁以上)的比例相对较高,但与传统数据源存在较大差异。NSDUH数据收集的是美国非机构化人口的调查结果,受到调查对象的诚实度和调查范围的限制。而Twitter数据则可以在一定程度上弥补这些限制,因为Twitter的匿名性可以部分缓解特定人口群体的低估或高估倾向。此外,Twitter数据也受到特定人口群体的倾向影响,因此仍需谨慎分析和解释数据。总体来说,文章结果表明,利用社交媒体数据可以提供有关药物使用和人口统计特征的信息,有望成为传统数据源的有益补充。
参考资料
Yang, Y. C., Al-Garadi, M. A., Love, J. S., Cooper, H. L., Perrone, J., & Sarker, A. (2023). Can accurate demographic information about people who use prescription medications nonmedically be derived from Twitter?. Proceedings of the National Academy of Sciences, 120(8), e2207391120.