


关于TikTok Scraper
TikTok Scraper是一款针对TikTok的数据收集工具,该工具可以帮助广大用户从TikTok快速收集和下载各种有用的信息,其中包括视频、趋势、标签、音乐、feed和URL等元数据。
值得一提的是,作为一个纯数据爬取工具,该工具不需要进行登录或设置密码,因为TikTok Scraper使用了TikTok Web API来收集媒体信息和相关元数据。
注意:当前版本的TikTok Scraper不支持无水印下载视频。
功能介绍
1、从用户、标签、趋势或音乐Id页面下载的帖子元数据(不限量)
2、将帖子元数据存储为JSON/CSV文件
3、下载媒体数据,并保存为ZIP文件
4、从CLI下载单个视频文件
5、使用签名URL向TikTok API发送自定义请求
6、从用户、标签和单个视频页面提取元数据
7、保存之前的爬取进度,只下载以前没有下载过的新视频。此功能仅在CLI中有效,并且仅在“下载”标志处于启在CLI中查看和管理以前下载的帖子历史记录用状态时有效。
8、在CLI中查看和管理以前下载的帖子历史记录
9、以批处理模式爬取并下载文件中指定的用户、标签、音乐feed和单个视频
工具安装
TikTok Scraper要求本地设备安装并配置好Node.js v10+环境。
通过NPM安装
npm i -g tiktok-scraper
通过YARN安装
yarn global add tiktok-scraper
工具使用
命令行终端
$ tiktok-scraper --help Usage: tiktok-scraper <command> [options] Commands: tiktok-scraper user [id] Scrape videos from username. Enter only username tiktok-scraper hashtag [id] Scrape videos from hashtag. Enter hashtag without # tiktok-scraper trend Scrape posts from current trends tiktok-scraper music [id] Scrape posts from a music id number tiktok-scraper history View previous download history tiktok-scraper from-file [file] [async] Scrape users, hashtags, music, videos mentioned in a file. 1 value per 1 line Options: --version Show version number [boolean] --session Set session cookie value. Sometimes session can be helpful when scraping data from any method [default: ""] --session-file Set path to the file with list of active sessions. One session per line! [default: ""] --timeout Set timeout between requests. Timeout is in Milliseconds: 1000 mls = 1 s [default: 0] --number, -n Number of posts to scrape. If you will set 0 then all posts will be scraped [default: 0] --since Scrape no posts published before this date (timestamp). If set to 0 the filter is deactived [default: 0] --proxy, -p Set single proxy [default: ""] --proxy-file Use proxies from a file. Scraper will use random proxies from the file per each request. 1 line 1 proxy. [default: ""] --download, -d Download video posts to the folder with the name input [id] [boolean] [default: false] --asyncDownload, -a Number of concurrent downloads [default: 5] --hd Download video in HD. Video size will be x5-x10 times larger and this will affect scraper execution speed. This option only works in combination with -w flag [boolean] [default: false] --zip, -z ZIP all downloaded video posts [boolean] [default: false] --filepath File path to save all output files. [default: "/Users/karl.wint/Documents/projects/javascript/tiktok-scraper"] --filetype, -t Type of the output file where post information will be saved. 'all' - save information about all posts to the` 'json' and 'csv' [choices: "csv", "json", "all", ""] [default: ""] --filename, -f Set custom filename for the output files [default: ""] --store, -s Scraper will save the progress in the OS TMP or Custom folder and in the future usage will only download new videos avoiding duplicates [boolean] [default: false] --historypath Set custom path where history file/files will be stored [default: "/var/folders/d5/fyh1_f2926q7c65g7skc0qh80000gn/T"] --remove, -r Delete the history record by entering "TYPE:INPUT" or "all" to clean all the history. For example: user:bob [default: ""] --webHookUrl Set webhook url to receive scraper result as HTTP requests. For example to your own API [default: ""] --method Receive data to your webhook url as POST or GET request [choices: "GET", "POST"] [default: "POST"] --help Show help [boolean]
工具使用演示
tiktok-scraper user USERNAME -d -n 100 --session sid_tt=dae32131231 tiktok-scraper trend -d -n 100 --session sid_tt=dae32131231 tiktok-scraper hashtag HASHTAG_NAME -d -n 100 --session sid_tt=dae32131231 tiktok-scraper music MUSIC_ID -d -n 50 --session sid_tt=dae32131231 tiktok-scraper video https://www.tiktok.com/@tiktok/video/6807491984882765062 -d tiktok-scraper history tiktok-scraper history -r user:bob tiktok-scraper history -r all tiktok-scraper from-file BATCH_FILE ASYNC_TASKS -d
工具使用样例
命令行终端使用
从用户{USERNAME}爬取300条视频帖子,并将帖子元数据保存至CSV(-t csv)文件中:
tiktok-scraper user USERNAME -n 300 -t csv --session sid_tt=asdasd13123123123adasda Output: CSV path: /bla/blah/USERNAME_1552945544582.csv
从哈希标签{HASHTAG_NAME}爬取100条帖子数据,下载(-d)并保存为ZIP(-z)文档,将帖子元数据保存为JSON和CSV文件(-t all):
tiktok-scraper hashtag HASHTAG_NAME -n 100 -d -z -t all --session sid_tt=asdasd13123123123adasda Output: ZIP path: /bla/blah/HASHTAG_NAME_1552945659138.zip JSON path: /bla/blah/HASHTAG_NAME_1552945659138.json CSV path: /bla/blah/HASHTAG_NAME_1552945659138.csv
从趋势部分爬取50条帖子,下载(-d)并保存为ZIP(-z)文档,将帖子元数据保存为CSV文件(-t csv):
tiktok-scraper trend -n 50 -d -z -t csv --session sid_tt=asdasd13123123123adasda Output: ZIP path: /bla/blah/trend_1552945659138.zip CSV path: /bla/blah/tend_1552945659138.csv
从指定音乐ID爬取100条帖子,下载(-d)并保存为ZIP(-z)文档,将帖子元数据保存为CSV文件(-t csv):
tiktok-scraper music MUSICID -n 100 -d -z -t csv --session sid_tt=asdasd13123123123adasda Output: ZIP path: /bla/blah/music_1552945659138.zip CSV path: /bla/blah/music_1552945659138.csv
从用户{USERNAME}下载最新的20条发布视频,保存下载进度防止重复下载:
tiktok-scraper user USERNAME -n 20 -d -s --session sid_tt=asdasd13123123123adasda Output: Folder Path: /User/Bob/Downloads/USERNAME
管理下载历史

我们可以通过命令行工具查看历史数据:
tiktok-scraper history
删除单条历史记录:
tiktok-scraper history -r TYPE:INPUT tiktok-scraper history -r user:tiktok tiktok-scraper history -r hashtag:summer tiktok-scraper history -r trend
设置好自定义路径后,每次运行你都需要告诉工具文件路径:
tiktok-scraper hashtag summer -s -d -n 10 --historypath /Blah/Blah/Blah
删除所有的记录::
tiktok-scraper history -r all
批处理爬取并下载内容
## User feed by username <---- this is just a comment and hence it is not important tiktok charlidamelio sam bob ## User feed by user id id:12312312312 ## Hashtag feed #love #summer #story ## Music feed music:3242234234 music:46646 music:23423424234 ## Single Videos. Each video will be downloaded without the watermark https://www.tiktok.com/@shalisavdlaan/video/6788483055796391173 https://www.tiktok.com/@officialsaarx/video/6785180623263911174 https://www.tiktok.com/@dominos_nl/video/6786669305623842053 https://www.tiktok.com/@jessiejikki/video/6620697278451551493 https://www.tiktok.com/@.one_man_army/video/6798822211307310338
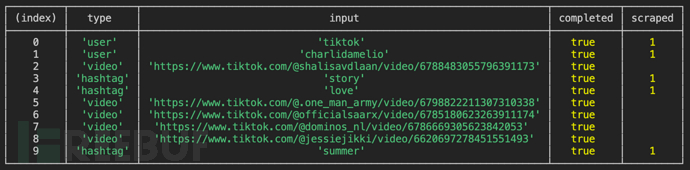
输出文件样例

JSON输出样例
视频Feed
{
headers: {
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.80 Safari/537.36',
referer: 'https://www.tiktok.com/',
cookie: 'tt_webid_v2=689854141086886123'
},
collector:[{
id: 'VIDEO_ID',
text: 'CAPTION',
createTime: '1583870600',
authorMeta:{
id: 'USER ID',
name: 'USERNAME',
following: 195,
fans: 43500,
heart: '1093998',
video: 3,
digg: 95,
verified: false,
private: false,
signature: 'USER BIO',
avatar:'AVATAR_URL'
},
musicMeta:{
musicId: '6808098113188120838',
musicName: 'blah blah',
musicAuthor: 'blah',
musicOriginal: true,
playUrl: 'SOUND/MUSIC_URL',
},
covers:{
default: 'COVER_URL',
origin: 'COVER_URL',
dynamic: 'COVER_URL'
},
imageUrl:'IMAGE_URL',
videoUrl:'VIDEO_URL',
videoUrlNoWaterMark:'VIDEO_URL_WITHOUT_THE_WATERMARK',
videoMeta: { width: 480, height: 864, ratio: 14, duration: 14 },
diggCount: 2104,
shareCount: 1,
playCount: 9007,
commentCount: 50,
mentions: ['@bob', '@sam', '@bob_again', '@and_sam_again'],
hashtags:
[{
id: '69573911',
name: 'PlayWithLife',
title: 'HASHTAG_TITLE',
cover: [Array]
}...],
downloaded: true
}...],
//If {filetype} and {download} options are enbabled then:
zip: '/{CURRENT_PATH}/user_1552963581094.zip',
json: '/{CURRENT_PATH}/user_1552963581094.json',
csv: '/{CURRENT_PATH}/user_1552963581094.csv'
}
getUserProfileInfo
{
secUid: 'MS4wLjABAAAAv7iSuuXDJGDvJkmH_vz1qkDZYo1apxgzaxdBSeIuPiM',
userId: '107955',
isSecret: false,
uniqueId: 'tiktok',
nickName: 'TikTok',
signature: 'Make Your Day',
covers: ['COVER_URL'],
coversMedium: ['COVER_URL'],
following: 490,
fans: 38040567,
heart: '211522962',
video: 93,
verified: true,
digg: 29,
}
getHashtagInfo
{
challengeId: '4231',
challengeName: 'love',
text: '',
covers: [],
coversMedium: [],
posts: 66904972,
views: '194557706433',
isCommerce: false,
splitTitle: ''
}
getVideoMeta
{
headers: {
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.80 Safari/537.36',
referer: 'https://www.tiktok.com/',
cookie: 'tt_webid_v2=689854141086886123'
},
collector:[{
id: '6807491984882765062',
text: 'We’re kicking off the #happyathome live stream series today at 5pm PT!',
createTime: '1584992742',
authorMeta: { id: '6812221792183403526', name: 'blah' },
musicMeta:{
musicId: '6822233276137213677',
musicName: 'blah',
musicAuthor: 'blah'
},
imageUrl: 'IMAGE_URL',
videoUrl: 'VIDEO_URL',
videoUrlNoWaterMark: 'VIDEO_URL_WITHOUT_THE_WATERMARK',
videoMeta: { width: 480, height: 864, ratio: 14, duration: 14 },
covers:{
default: 'COVER_URL',
origin: 'COVER_URL'
},
diggCount: 49292,
shareCount: 339,
playCount: 614678,
commentCount: 4023,
downloaded: false,
hashtags: [],
}]
}
getMusicInfo
{
music: {
id: '6882925279036066566',
title: 'doja x calabria',
playUrl: 'dfdfdfdf',
coverThumb:
'dfdfdf',
coverMedium:
'dfdfdf',
coverLarge:
'fdfdf',
authorName: 'bryce',
original: true,
playToken:
'ffdfdf',
keyToken: 'dfdfdfd',
audioURLWithcookie: false,
private: false,
duration: 46,
album: '',
},
author: {
id: '6835300004094166021',
uniqueId: 'mashupsbybryce',
nickname: 'bryce',
avatarThumb:
'dfdfd',
avatarMedium:
'dfdfdf',
avatarLarger:
'dfdfdf',
signature: 'hi ily :)\n70k sounds cool tbh\nfollow my soundcloud & insta',
verified: false,
secUid: 'MS4wLjABAAAA1_5bjLAamayD4rv3q49qJGa_7dZ5jzExTO0ozOybqIwwhw5TAg_iM25lkO94DM3K',
secret: false,
ftc: false,
relation: 0,
openFavorite: false,
commentSetting: 0,
duetSetting: 0,
stitchSetting: 0,
privateAccount: false,
},
stats: { videoCount: 361700 },
shareMeta: {
title: 'bryceyouloser | ♬ doja x calabria | on TikTok',
desc: '361.0k videos - Watch awesome short ' + 'videos created with ♬ doja x calabria',
},
};
许可证协议
本项目的开发与发布遵循MIT开源许可证协议。
项目地址
TikTok Scraper:【GitHub传送门】
参考资料
https://www.tiktok.com/
https://nodejs.org/
https://github.com/drawrowfly/tiktok-scraper/tree/master/examples/CLI/Examples.md
https://github.com/drawrowfly/tiktok-scraper/tree/master/examples/CLI/DownloadHistory.md
https://github.com/drawrowfly/tiktok-scraper/tree/master/examples/CLI/BatchDownload.md