

第一章
1. 什么是数据挖掘?
数据挖掘就是从大量的、不完全的、有噪声的、模糊的、随机的实际应用数据中,提取出隐含在其中的、人们事先不知道的、但又是潜在有用的信息和知识的过程。
Data mining is a process from which we can get hidden, unknown, but potentially useful information and knowledge from a lot of incomplete, noisy, fuzzy and random practical application data.
2. 与数据挖掘类似的术语有哪些?
- 数据库中的知识发现-Knowledge discovery(mining) in databases (KDD)
- 知识提取-Knowledge extraction
- 数据/模式分析-data/pattern analysis
- 数据考古-data archeology
- 数据疏浚-data dredging
- 信息收获-information harvesting
- 商业智能-business intelligence
3. 可以挖掘什么类型的数据?
- 数据库数据。
- 数据仓库。数据仓库是一个从多个数据源收集的信息存储库,存放在一致的模式下,并且通常驻留在单个站点上。
- 事务数据。一般来说,事务数据库的每个记录代表一个事务,如顾客的一次购物、一个航班订票,或一个用户的网页点击。
- 其他类型的数据。如数据流,空间数据,超文本和多媒体数据, 图和网状数据, 万维网。
4. 可以挖掘什么类型的模式?
- 数据特征化与数据区分。数据特征化(data characterization)是目标类数据的一般特性或特征的汇总。数据区分(data discrimination)是将目标类数据对象的一般特性与一个或多个对比类对象的一般性进行比较。
- 频繁模式、关联和相关性挖掘。频繁模式(frequent pattern)是在数据中频繁出现的模式,存在多种类型的频繁模式,包括频繁项集、频繁子序列(序列模式)和频繁子结构。
- 分类与回归。
- 聚类分析。
- 离群点分析。
5. 知识发现过程包括哪些步骤?/数据库中的知识发现过程由哪几个步骤组成?
- 数据清理-data cleaning(填写空缺的值、平滑噪声数据,识别、删除离群点,解决不一致性)
- 数据集成-data integration(集成多个数据库、数据立方体或文件中的数据)
- 数据规约-data reduction(得到数据集的简化表示)
- 数据变换-data transformation(将数据变换成适合挖掘的模式)
- 数据挖掘-Knowledge discovery(mining) in databases
- 模式评估-pattern evaluation(根据某种兴趣度量值,识别代表知识的真正有趣的模式)
- 知识表示-knowledge presentation(使用可视化和知识表示技术,向用户提供挖掘的知识)
第二章
1. 描述数据的中心趋势与离散度都使用哪几个度量值?如何计算?
描述数据的中心趋势:
- 均值mean
- 算术均值
- 加权均值Weighted arithmetic mean
- 截尾均值Trimmed mean:丢弃高低极端值后的均值
- 中位数median
- 众数mode
- 中列数midrange:最大值和最小值的平均值
描述数据的离散度:
- 极差range:最大值和最小值之差
- 四分位数
- Q1:第一个四分位数,是第25个百分数
- Q2:第二个四分位数,中位数
- Q3:第三个四分位数,是第75个百分数
- 四分位数极差IQR=Q3-Q1
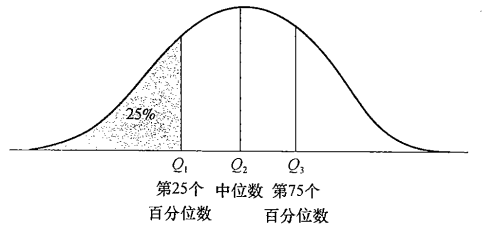
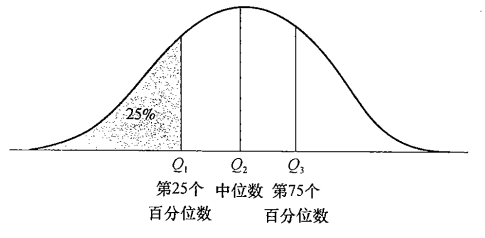
2. 五数概括的含义。
五数概括法(Five-number Summary)是最基础的描述分析方法,描述数据分布的离散程度。
- 最小值-Minimum
- Q1
- 中位数-Median
- Q3
- 最大值-Maximum
3. 给出一批数据,能够度量其中心趋势与离散特征,能够绘制盒图。
盒图boxplot体现了五数概括:
- 端点:盒的端点一般在四分位数上,使得盒的长度是四分位数极差IQR。
- 盒内线:中位数用盒内的线标记。
- 盒外线(胡须):胡须延伸到最小值和最大值。
- 离群点:仅当最高和最低观测值超过四分位数不到1.5IQR时,胡须扩展到它们;否则,以离群点的形式个别地绘出。
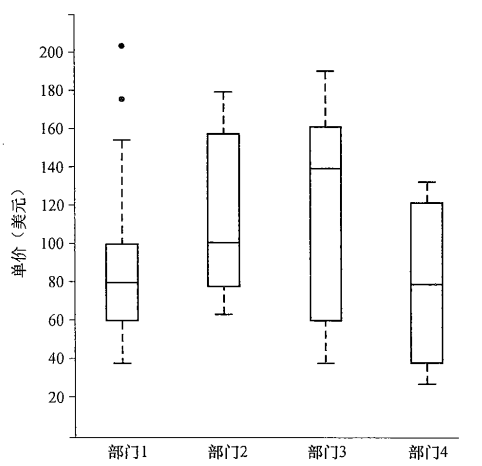
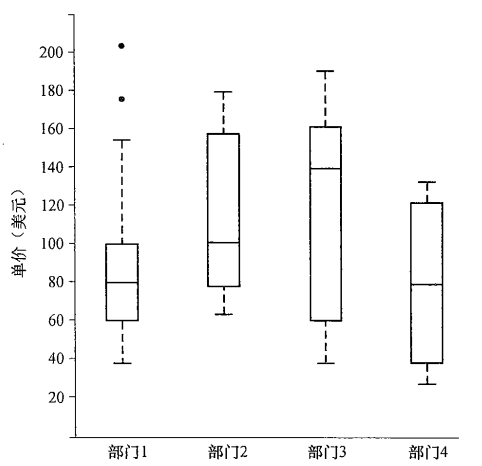
4. 什么是Q-Q图?
Q-Q图(分位数-分位数图)是一种散点图,横坐标为某一样本的分位数,纵坐标为另一样本的分位数,横坐标和纵坐标组成的散点图代表同一累计概率所对应的分位数。
5. 各种距离、范数的计算。
- 曼哈顿距离-1范数
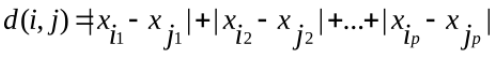
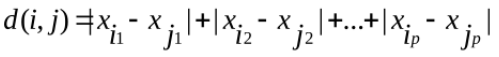
- 欧几里得距离-2范数
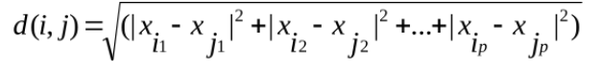
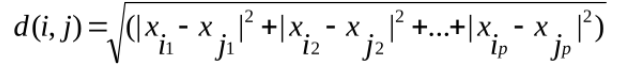
- 上确界距离-∞范数
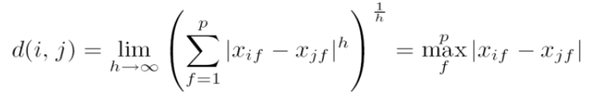
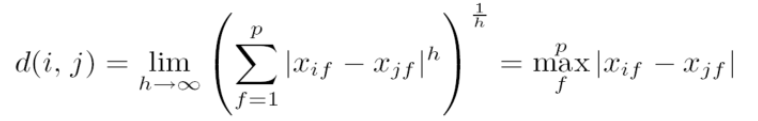
- 闵可夫斯基距离-p范数
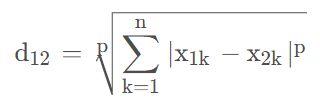
6. 余弦相似性的计算。




第三章
1. 什么是数据清理?
填写空缺的值、平滑噪声数据,识别、删除离群点,解决不一致性
2. 什么是数据集成?
集成多个数据库、数据立方体或文件中的数据
3. 什么是数据归约?
数据归约用来得到数据集的归约表示,它小得多,但仍接近于保持原始数据的完整性。也就是说,在归约后的数据集上挖掘将更有效,仍然产生相同(或几乎相同)的分析结果。
4. 脏数据形成的原因有哪些?
- 输入错误
- 系统故障
- 数据集成问题
- 数据更新问题
- 人为破坏
5. 数据清理时,对空缺值有哪些处理方法?
- 忽略元组
- 人工填写缺失值
- 使用一个全局常量填充缺失值
- 使用属性的中心度量填充缺失值
- 使用与给定元组属同一类的所有样本的属性均值或中位数
- 使用最可能的值填充缺失值
6. 什么是数据变换?包括哪些内容?
将数据变换或统一成适合于挖掘的形式。
策略:
- 光滑
- 属性构造
- 聚集
- 规范化
- 离散化
- 由标称数据产生概念分层
7. 给出一批数据,能够进行数据变换 (min-max 规范化,Z-score 规范化)。
- min-max 规范化——[min_A, max_A]->[new_min_A, new_max_A]
v'_i=\frac{v_i-min_A}{max_A-min_A}(new\_max_A-new\_min_A)+new\_min_A
- Z-score 规范化
v'_i=\frac{v_i-\bar{A}}{\sigma(A)}
其中 \bar{A} 为均值, \sigma(A) 为标准差。
\sigma^2=\frac{1}{N}\sum_{i=1}^{N}{(x_i-\bar{x})^2}
8. 数据归约的策略包括哪些?
- 维归约:小波变换;主成分分析;特征子集选择,特征生成
- 数量规约:回归和对数线性模型;直方图,聚类,抽样;数据立方体聚集
- 数据压缩
第四章
1. 什么是数据仓库?
数据仓库是一个面向主题的、集成的、时变的、非易失的数据集合,支持管理决策制定。
A data warehouse is a subject-oriented, integrated, time-variant and nonvolatile collection of data in support of management’s decision-making process.
2. 数据仓库的主要特征是什么?
①面向主题的:数据仓库围绕一些主题,如顾客、供应商和销售组织。数据仓库关注决策者的数据建模与分析,而不是构造组织机构的日常操作和数据处理。因此,数据仓库派出对于决策无用的数据,提供特定主题的简明视图。
②集成的:通常,构造数据仓库是将多个异种数据源,如关系仓库、一般文件和联机处理事务记录,集成在一起。使用数据清理和数据集成技术,确保命名约定、编码结构、属性度量的一致性。
③时变的:数据存储从历史的角度提供信息。数据仓库中的关键结构,隐式或显式地包含时间元素。
④非易失的:数据仓库总是物理地分离存放数据(physically separate store):这些数据源于操作环境下的应用数据。由于这种分离,数据仓库不需要事务处理、恢复和并行控制机制。通常,它只需要两种数据访问:数据的初始化装入(initial loading of data)和数据访问(access of data)。
3. 多维数据模型上的 OLAP 操作包括哪些?
联机分析处理(OLAP)on-line analytical processing是一种软件技术,它使分析人员能够迅速、一致、交互地从各个方面观察信息,以达到深入理解数据的目的。
典型的OLAP操作及其含义 Typical OLAP Operations
- 上卷(Roll-up/Drill up):汇总数据,通过维的概念分层向上攀升或者是维归约来汇总数据
- 下钻(Drill-down/roll down):上卷的逆操作,从高层的汇总到低层汇总,或者是观察更详细的数据,或者是引入一个新的维
- 切片切块(Slice and Dice):投影和选择
- 旋转(Pivot/rotate):对立方体的重定位,还有可视化,或者将一个3维的立方体转化为一个二维的平面序列
- 钻过(drill across):执行涉及多个事实表的查询;
- 钻透(drill through):使用关系SQL机制,钻到数据立方体的底层,到后端关系表


4. OLAP 服务器类型有哪几种?
- 关系 OLAP(ROLAP)服务器:使用关系的或者扩展的DBMS来存储和管理数据仓库数据以及OLAP的中间件,包括每个DBMS的后端优化,还有聚集导航的逻辑实现,以及附加的工具和服务,有比较大的可伸缩性
- 多维 OLAP(MOLAP)服务器:基于稀疏数组的多维存储引擎,对预计算的汇总数据进行快速处理
- 混合 OLAP(HOLAP)服务器:结合关系OLAP服务器和多维OLAP服务器,集成了他们的优点,有更大的灵活性
- 特殊OLAP服务器:在星型和雪花型模式上支持SQL查询
5. 将下列缩略语复原:OLAP, OLAM, FP-tree, DMQL, KDD, OLTP, DBMS, AOI.
- OLAP:联机分析处理 On-Line Analytical Processing
- OLAM:联机分析挖掘 On-Line Analytical Mining
- FP-tree:频繁模式树 frequent pattern tree
- DMQL:数据挖掘查询语言 Data Mining Query Language
- KDD:数据库中的知识发现 Knowledge discovery(mining) in databases
- OLTP:联机事务处理 On-Line Transaction Processing
- DBMS:数据库管理系统 Database Management Systems
- AOI:面向属性的归纳(学习) Attribute-Oriented Induction是一种面向关系数据库查询的、基于属性概化的、联机的数据分析处理技术(OLAP)的知识发现方法。
6. 什么是数据集市?
数据集市(Data Mart),也叫数据市场,数据集市就是满足特定的部门或者用户的需求,按照多维的方式进行存储,包括定义维度、需要计算的指标、维度的层次等,生成面向决策分析需求的数据立方体。
7. 多维数据模型的三种模式是什么?
- 星形模式(star schema):中间的事实表连向一系列的维表。A fact table in the middle connected to a set of dimension tables
- 雪花模式(snowflake schema):雪花模式是星形模式的变种,其中某些维表被规范化,因而把数据进一步分解到附加的表中。结果模式图形成类似于雪花的形状。A refinement of star schema where some dimensional hierarchy is normalized into a set of smaller dimension tables, forming a shape similar to snowflake
- 事实星座模式(Fact Constellation):数据仓库由多个主题构成,包含多个事实表,而维表是公共的,可以共享,这种模式可以看做星型模式的汇集,因而称作星系模式或者事实星座模式。
8. 给出一个度量函数,能够区分属于哪一类。
度量可根据所用的聚集函数分为三类:
- 分布聚集函数: count() sum() min() max()
- 代数聚集函数:每个参数可用一个分布聚集函数求得。
- E.g. avg()=sum()/count() ,类似的,min_N() max_N() standard_deviation()
- 整体聚集函数:median() mode() rank()
9. 给定数据立方体的维数,能够计算各D方体有几个,方体总数有多少?
设定维数为4,则
- 0-D方体:C(4, 0)=1个
- 1-D方体:C(4, 1)=4个
- 2-D方体:C(4, 2)=6个
- 3-D方体:C(4, 3)=4个
- 4-D方体:C(4, 4)=1个
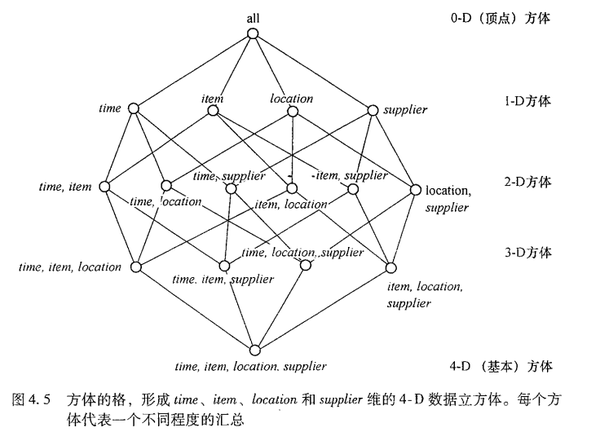
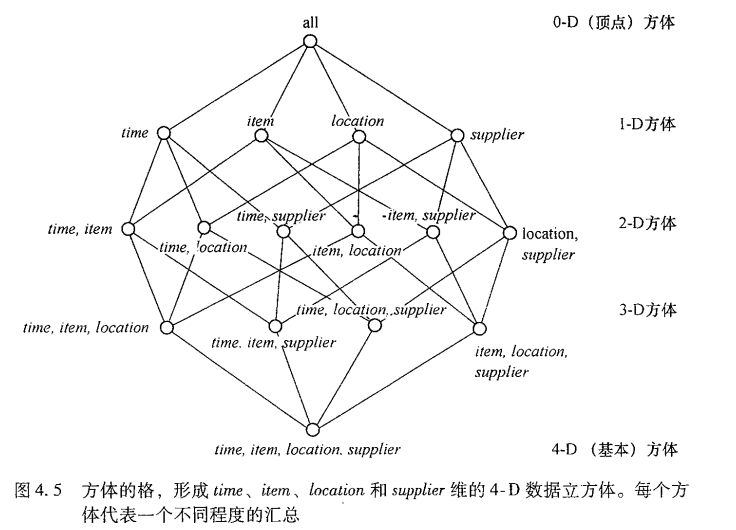
10. 基本方体、顶点方体的概念。
数据立方体可以被看成是一个方体的格,每个方体用一个group-by表示。
数据立方体是对多维数据存储的一种比喻,这种数据的物理存储不同于它的逻辑表示。
存放最低层汇总的方体称为基本方体。
0-D方体存放最高层的汇总,称作顶点方体(all)。
11. 面向属性的归纳中,针对各种不同类型的属性应该如何处理。
- 属性删除 attribute removal:某个属性上有不同的值,但是(情况1)不能泛化或(情况2)属性已经进行了概念分层。
- 属性泛化 attribute generalization:某个属性上有大量不同的值,并且该属性上存在泛化操作符的集合,则选择一个操作符来泛化该属性。
- 属性阈值控制 attribute threshold control:典型的取值范围一般为2-8.
- 广义关系阈值控制 generalized relation threshold control:如果广义关系中不同元组的个数超过该阈值,应当进一步泛化,否则,不再进一步泛化。
第五章
1. 指定数据挖掘任务的五种原语分别是什么?
- 任务相关数据-Task relevant data
- 要挖掘的知识类型-Type of knowledge to be mined
- 背景知识-Background knowledge
- 模式兴趣度度量-Pattern interestingness measurements
- 发现模式的可视化-Visualization of discovered patterns
2. 给出DMQL描述的查询,能够将数据挖掘原语对号入座。


3. 常用的四种概念分层类型。
- 模式分层 Schema hierarchy
- 集合分组分层 Set-grouping hierarchy
- 操作导出的分层 Operation-derived hierarchy
- 基于规则的分层 Rule-based hierarchy
4. 常用的四种兴趣度的客观度量。
- Certainty —— 确定性
- Utility —— 实用性
- Novelty —— 新颖性
- Simplicity —— 简单性
第六章
1. 什么是强关联规则?
衡量关联规则有两个标准,一个叫支持度,另一个叫置信度。如果两个都高于阈值,那么叫做强关联规则。如果只有一个高于阈值,则称为弱关联规则。
2. 支持度的含义。
支持度Support:表示同时包含A和B的事务占所有事务的比例。
support(A\Rightarrow B)=P(A联合 B)
3. 置信度的含义。
置信度Confidence:表示使用包含A的事务中同时包含B事务的比例,即同时包含A和B的事务占包含A事务的比例。
confidence(A\Rightarrow B)=P(B|A)=P(A联合B)/P(A)
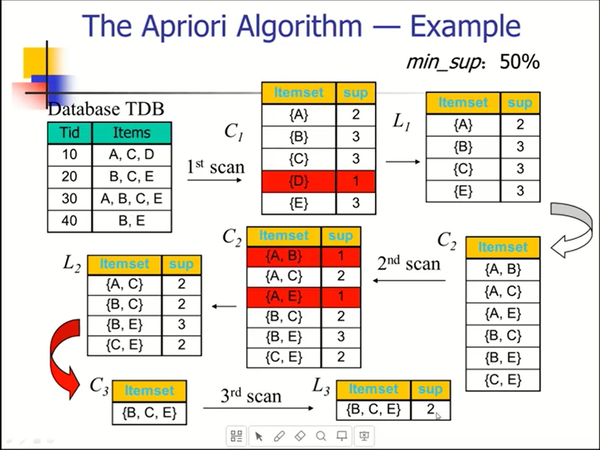
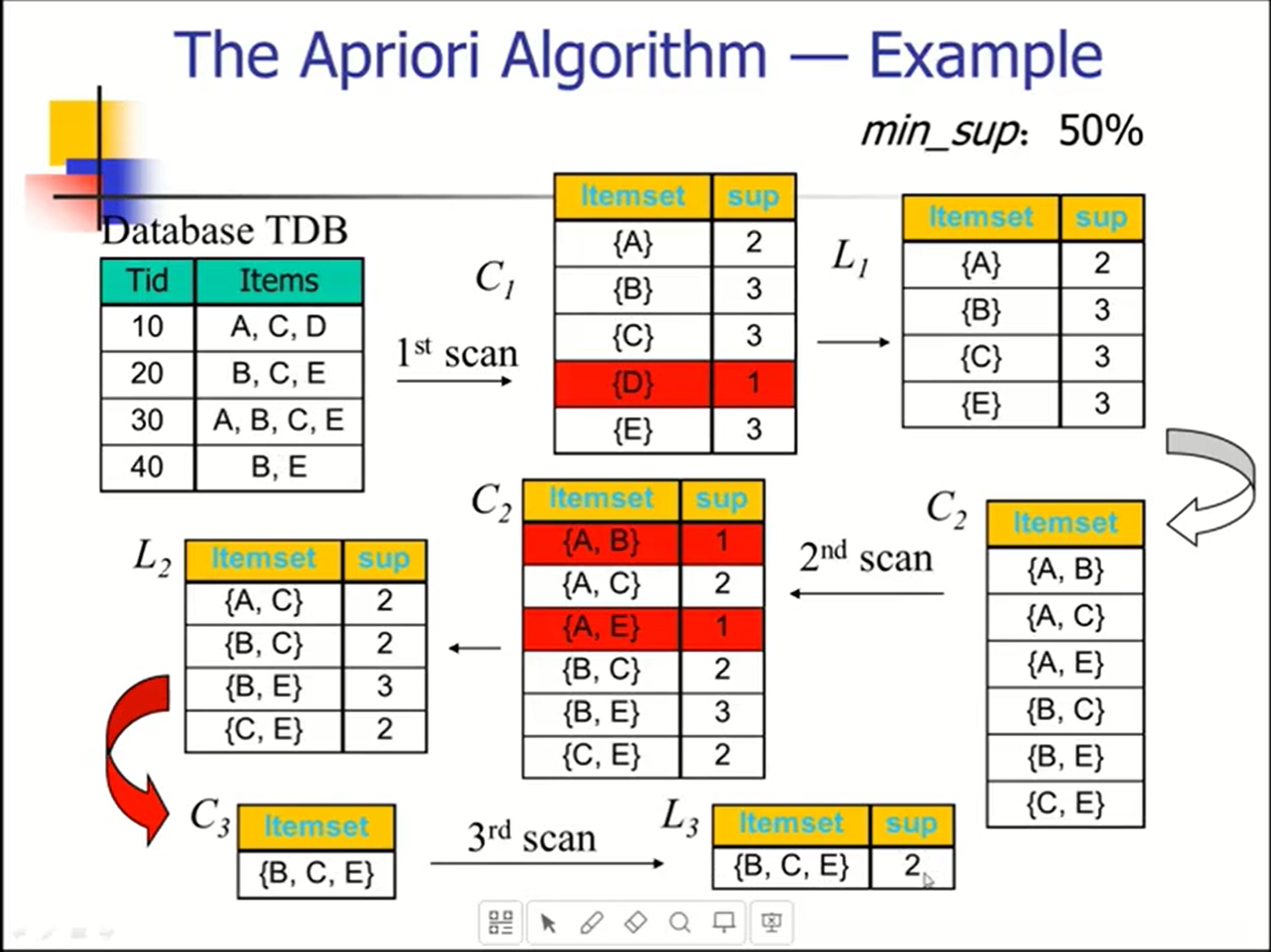
4. 己知事务数据库,给定最小支持度,会求所有的频繁项集和它们的支持度,列出强关联规则。
Apiori算法
- 连接
- 剪枝
频繁项集的任何子集必然是频繁的。
Any subset of a frequent itemset must be frequent .
关键步骤:
- 寻找频繁项集:寻找具有最小支持度的项集。
- 使用频繁项集来生成关联规则。
缺点:
- 需要多次扫描数据集
- 可能会产生庞大的候选集
5. 改进 Apriori 算法效率有哪几种思路?
- 减少对事务数据库的扫描次数。Reduce passes of transaction database scans.
- 缩小产生的候选项集的数目。Shrink number of candidates.
- 改进对候选支持度的计算方法。Facilitate support counting of candidates.
6. 为什么FP-growth 算法优于 Apriori 算法?
FP-growth算法只对数据库扫描一次且不产生候选项集。而Apriori算法对于每个潜在的频繁项集都会扫描数据集判定给定的模式是否频繁,因此FP-growth算法要比Apriori算法快。
第七章
1. 什么是聚类分析?它与分类有什么区别?
- 什么是聚类分析:
根据数据的特征发现数据间的相似性,并把相似的数据对象分成簇。
What is cluster analysis?
Similar (or related) to one another within the same group
Dissimilar (or unrelated) to the objects in other groups
- 聚类和分类的区别:
聚类是一种无监督学习方法,不需要先验的类标签信息。分类则是一种监督学习方法,需要利用已知的类标签训练模型。
2. 什么是好的聚类方法?
一个好的聚类方法将产生高质量的聚类:
高的类内相似性:簇内的凝聚性
低的类间相似性:簇间的区分性
What is good clustering?
A good clustering method will produce high quality clusters
·high intra-class similarity: cohesive within clusters
·low inter-class similarity: distinctive between clusters