

最近,有传言称 Instagram 将关闭其 API,只允许企业合作伙伴访问。
由于 Instagram 的庞大用户群,数据抓取在这种情况下变得更加重要。 Instagram 是一个在每个角落都充满数据的平台。
我决定首先抓取我们可以在一个人的帐户页面上找到的任何数据,您可以通过https://instagram.com/访问该页面
让我们看看我的页面,例如https://instagram.com/manan.code
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--chkycTYi--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev-to-uploads .s3.amazonaws.com/i/jr2n2kirez6oc6qgmhgv.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--chkycTYi--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev-to-uploads .s3.amazonaws.com/i/jr2n2kirez6oc6qgmhgv.png)
这是我感兴趣的主要领域,我们可以从这里刮取什么以及如何刮取?右键点击页面,点击查看页面源代码,可以看到后面的源文件。
你会看到这样的东西——
[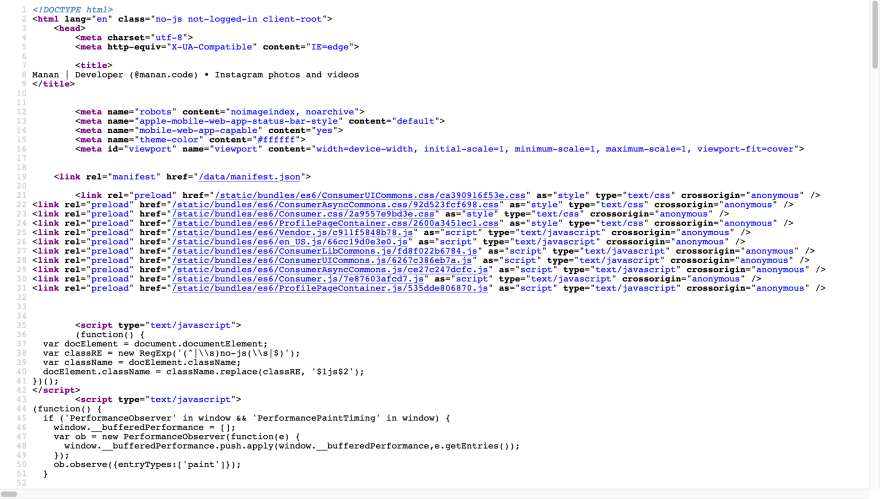 ](https://res.cloudinary.com/practicaldev/image/fetch/s--HOX7RUaE--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev-to-uploads .s3.amazonaws.com/i/5l98meync1h69cw5v870.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--HOX7RUaE--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev-to-uploads .s3.amazonaws.com/i/5l98meync1h69cw5v870.png)
现在乍一看,这似乎难以理解,而且似乎几乎不可能从中找到任何数据,这只是链接和脚本标签的海洋。
但是数据肯定在某个地方。
我做了一些挖掘,发现了基本上包含我们需要的一切的脚本标签。
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--2kEHIRBU--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev-to-uploads .s3.amazonaws.com/i/713yabdp73bh95d4nvuw.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--2kEHIRBU--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev-to-uploads .s3.amazonaws.com/i/713yabdp73bh95d4nvuw.png)
现在我们知道数据在哪里,让我们继续代码。
我们将使用 requests 模块和 BeautifulSoup。
因此,直到代码中的这一点,我们已经请求 Instagram 并获得了源代码,之后我们将其转换为 BeautifulSoup 对象,以便轻松找到我们需要的脚本标签。将其转换为 BeautifulSoup 对象后,我们使用 BeautifulSoup 库中的 find_all 函数,找到了所有的脚本标签,经过一些尝试和错误,我发现,我们需要的脚本标签是第 5 个,所以我们索引它适当地找到我们需要的脚本标签。
但是,我们还需要做一件事,现在我们拥有的不是字符串,我们无法将其切片以找到我们需要的东西。因此,我们访问脚本标签的内容。
下一步是找出我们需要的零件在哪里。
{"config":data_json
仔细观察,我找到了我们需要的数据的所有正确键,这是结果。

这标志着我们抓取 Instagram 之旅的结束!
查看我的视频,我在其中讨论了同样的事情-