

背景介绍
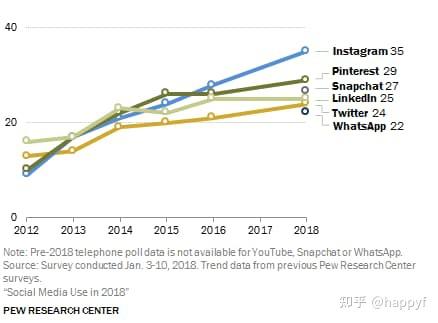
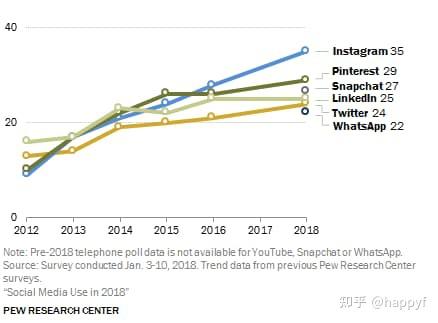
Instagram,中文名照片墙,是目前全球非常火的一款移动社交应用软件,随时随地分享抓拍下来的图片为彼此分享。并于2012年被Facebook收购。Instagram的日活跃用户已经突破5亿,使其仅次于Facebook和 YouTube的第三大社媒平台,并超过Twitter(3.26亿活跃用户)、Snapchat(1.5亿活跃用户)和Pinterest(2.5亿活跃用户)。同时,它作为以图片为主体的发布平台,每天在Instagram上发布的图片和视频总量超过1亿个。
Instagram作为挖掘用户意愿、对品牌的偏好以及口碑传播的平台。在Ins对全球用户的大规模问卷来看,有90%的用户至少会关注一个商家,同时,50%的被受访者对在Instagram上进行的广告宣传更感兴趣。有鉴于此,在100家国际品牌中,有90%的品牌已经拥有Instagram帐户,80%的品牌每周至少发布一则Instagram照片或视频。
同时,还值得数字化营销人员/品牌方注意的是,Instagram上的成年人比例最高,也就是说,具有更高的购买力。
具体来说,它可以用来作什么?在其官方案例中,有以下几点
- 通过摄影、照片拼贴和品牌创意提升购买意向
- 新产品发布后用户传播、口碑记录
- 触达更多客户
- 推广艺术家
挖掘Instagram的商业数据,从品牌、营销和学术角度,都有重要意义。本文将从数据特点介绍、数据获取、数据处理和基本的探索分析手段几个方面,带大家入门Ins商业数据挖掘。
Ins数据特点
Instagram的产品操作流程如下:
拍照/截屏-->滤镜特效(以lomo风为主的11种照片特效)-->添加说明/添加地点-->分享(可以共享到 Twitter 、Facebook、Tumblr、Flickr以及Foursquare,甚至新浪微博这些主流社交网络)。
同时Instagram基于这些照片建立了一个微社区,在这里你可以通过关注、评论、赞等操作与其他用户进行互动。
从整个操作路径,Ins的数据,有如下几种类型:
- 图像/视频
这是Ins上最主要的数据,相比于文字,图像具有更高的信息密度和参与度,所以,对它的挖掘,比Facebook、Twitter这种以文字为主的社交平台能更有价值。
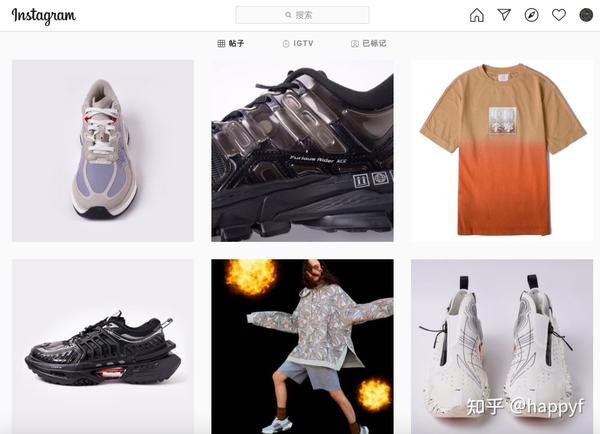
- 数值型
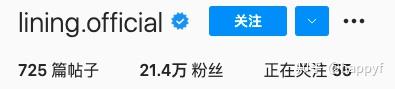
点赞数、分享、评论数、粉丝数等数值型数据,这部分信息作为最直观的数据,直接反映着一个账号、分享内容的质量。
- 文本类
文本是除图像外的另一种非结构化数据,包括一些表情、符号在内的图像,包括三种,
附着于图片上的Hashtag,作为图片的标签
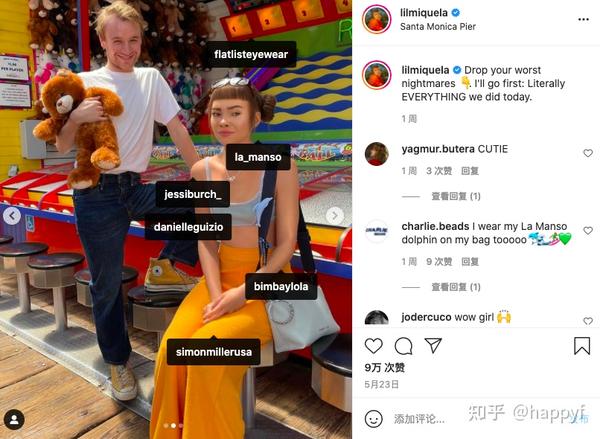
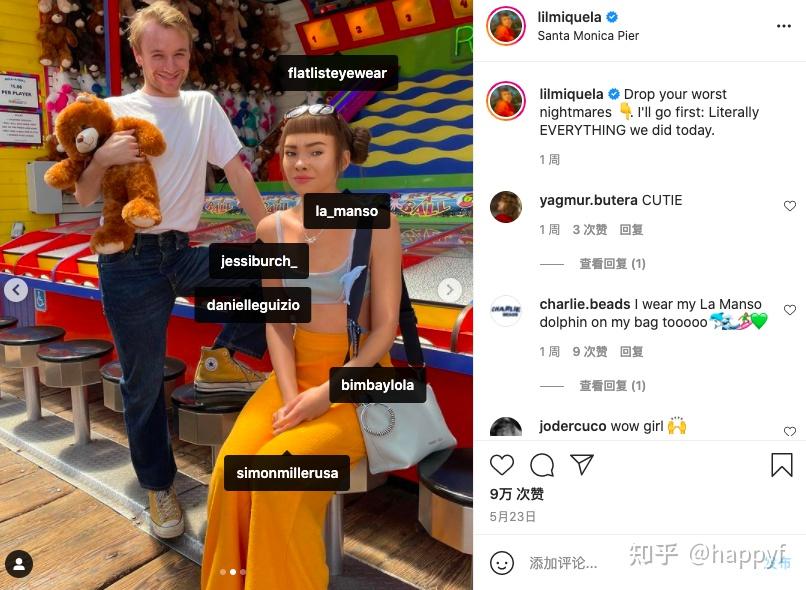
发布者的状态,通常是一段配图文字,可能与图片内容有关,也可能没关系
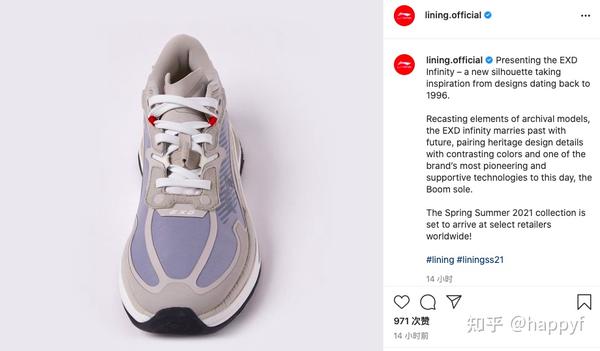
有关某一条Ins的评论,可以看到,ins上的评论相比较于电商、旅游等网站更加简单,甚至仅仅通过一些表情来表达对图片的态度。
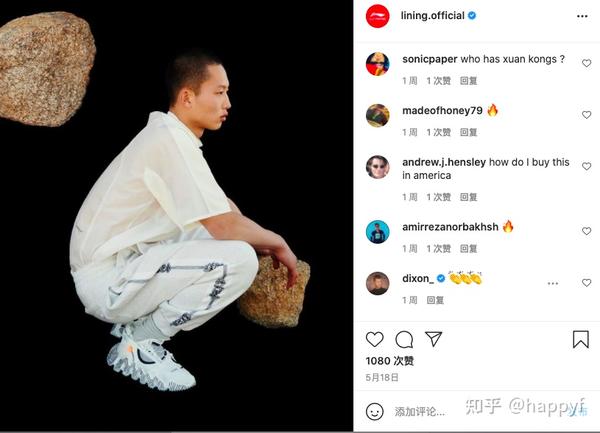
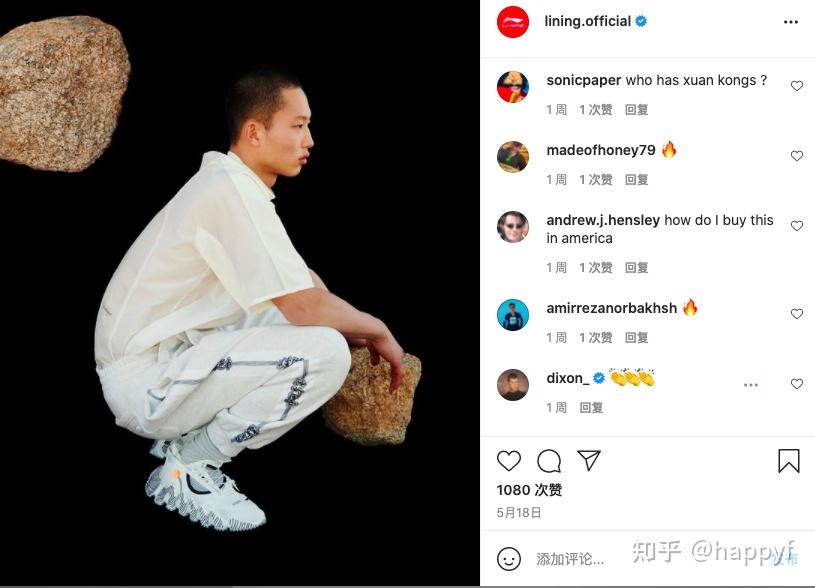
- 网络/空间数据
作为社交网站,粉丝、关注这些数据构成了一种有向图,在网络结构中,可以很直观的找到KOL、传播路径,同时,通过定位与演化。
抓取方案
巧妇难为无米之炊,数据的获取一直是每一个数据分析师的痛点,尤其是当我们知道一个平台有很重要的价值时。从零开始编写一个爬虫程序无异于灾难,但是好在互联网是一个神奇的地方,
安装
数据下载
注:首先保证能上Instagram。其次,如果有更多的资源和数据要求,可以采用多线程来抓。资源有限,按需抓取。
非结构化数据处理tips
通过instaloader抓取下来的数据,主要有三种格式。
- 基于json的数据解析
上文的数值型数据和部分文本型数据,被保存在json的压缩文件.xz文件中,需要从中解析出相关信息。JSON(JavaScript Object Notation, JS 对象简谱) 是一种轻量级的数据交换格式。
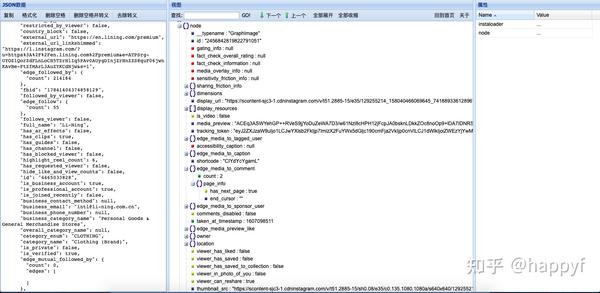
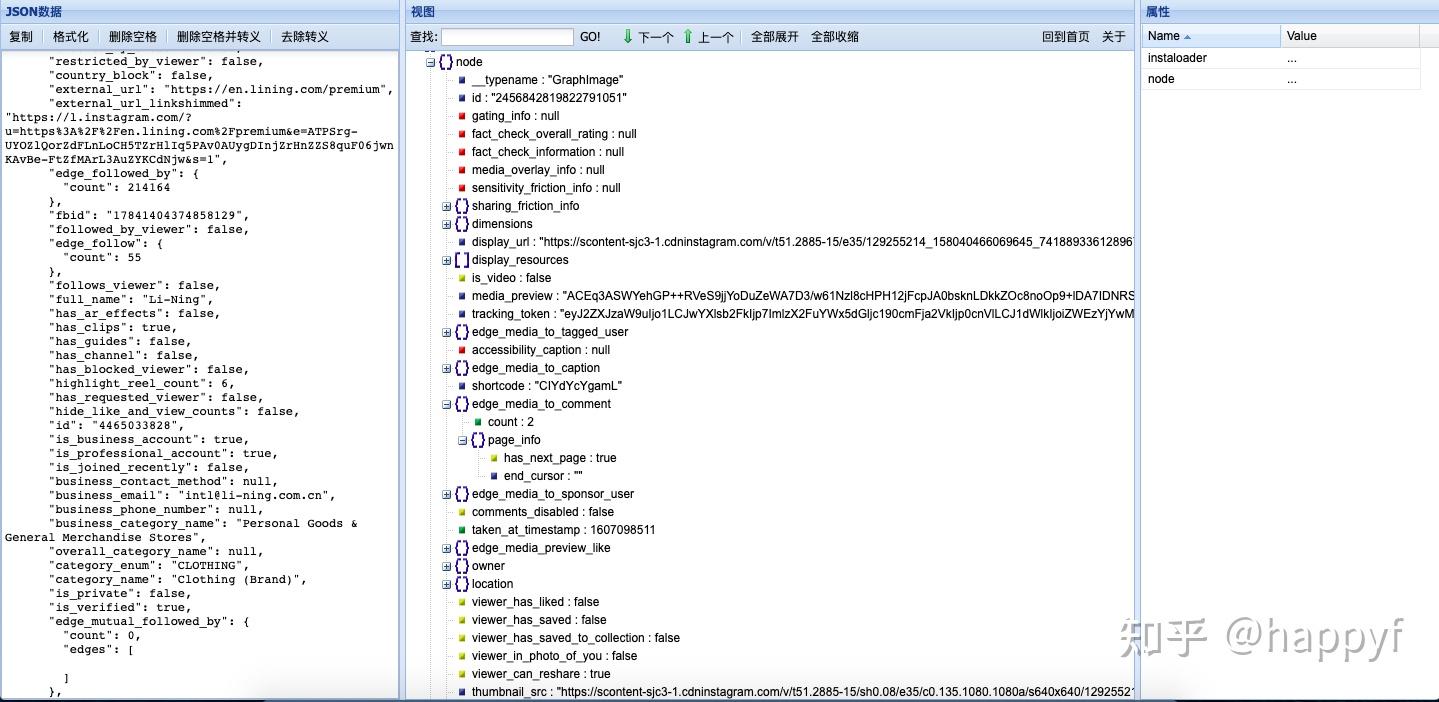
利用Python处理,其实就是一层层的剥离定位,首先将JSON格式转换成dict,然后去找想要的字段。
- 基于短文本的信息提取
文本类数据的信息提取,有两种方案
1)鉴于单词/词组是人们文本交流的基础手段。所以朴素的想法是,基于单词/自定义词典/语料库,从词频、共现概率,提取关于文本中的信息、主题或是相关情感
2)利用有标注的数据,可以根据标注标签,通过目前比较流行的机器学习/深度学习方法,发掘出高级/复杂的语义/情感。常见的模型包括利用LSTM/Transforemer/BERT等。
- 基于图像/视频的特征提取
1)传统的图像特征提取,可以利用opencv或是PIL来提取,主要是利用各种变换、卷积、滤波等手段,对图像进行增强、降噪和检测。
2)利用深度学习来提取图像中的特征,主要是利用CNN及相关架构,常见的特征提取框架有VGG、ResNet、Inception等。
由于针对深度学习的方法,需要大量的标注数据和硬件计算,所以多是采用迁移学习+微调的方案。也就是利用公开的数据集提取底层信息,再用少量个性化场景标注数据来提取上层的更加特异化的信息。
另外在百度、亚马逊、微软等大厂,针对常见的文本情感/图像侦测等常见场景有一些接口,当需要分析的数据不多时,可以免费调取接口。
具体的实现方案,我们将通过具体的一个案例来介绍——对国潮李宁的Ins近期的各类数据进行分析,看看能有什么有趣的发现。具体将会在后期陆续更新。