

本文介绍了 Haystack,这是一种为 Facebook 的照片应用程序设计的对象存储文件系统。Haystack 旨在为通过在大型社交网络中共享照片而看到的长尾请求提供服务。关键的特点是在访问元数据时避免磁盘操作。与使用 NAS 设备的传统方法相比,Haystack 提供了一种容错且简单的照片存储解决方案,其成本显着降低,吞吐量更高。
开源SeaweedFS文件系统实际上最初是基于Facebook设计的存储系统,如 Haystack、f4 和新的 Tectonic 存储系统。Haystack存储系统的设计解决了最大社交网络平台中真实世界的文件系统问题,并提供相当简单的解决方案且有效又易于来推理、实现和维护。
文件系统和CDN问题
在传统的基于 POSIX 的文件系统中,一切都被建模为一个文件,每个文件都有其关联的元数据,例如权限,这些元数据基本上不用于此类系统,从而导致相当大的空间浪费(每个图像的几个字节乘以数十亿和数十亿的存储图像)。
我们可以理解无用的元数据会浪费空间,但磁盘空间并不是真正的问题。当从磁盘读取图像时,这里的真正问题就会浮出水面。当从基于 POSIX 的文件系统中的磁盘读取图像时,会发生以下情况:
- 进行一次(通常更多)磁盘操作将文件名转换为inode 编号。一个索引节点是像该文件,其中包含有关该文件的信息,例如,文件类型,权限,UID,GID等文件的序列号
- 从磁盘获取 inode 的一项磁盘操作。
- 从磁盘获取文件本身的最终磁盘操作。
我们可以很容易地看到,仅仅读取文件的元数据就浪费了 2 个(或更多)磁盘操作。
CDN为频繁访问承担了负载,它还减轻了存储系统的负载,但是CDN 方法仅适用于最近请求的内容,但 facebook也有很多不那么受欢迎的内容(旧图片)产生大量流量,他们称之为长尾。
逻辑上讲,对长尾的请求将导致CDN中的缓存未命中,并会影响存储系统,从而导致高读取流量。当缓存更多热门内容时,因为CDN大小限制,有点旧的数据也会很快从CDN过期失效,因此几乎总是必须由存储系统提供所有大流量服务。
Haystack
旧的NFS系统中的主要吞吐量瓶颈是磁盘操作扇出(每次读取文件时再执行4次磁盘操作),这主要浪费在获取文件元数据上。我们一致认为,在主内存中加载所有元数据将消除这些磁盘操作,但由于其大小和存储的大量文件,这是不切实际的。因此,其主要思想是最小化每个文件的元数据,以便可以有效地将其加载到主内存中。
Haystack使用了一种直接的方法:它将多张照片存储在一个文件中,因此可以维护非常大的文件。请注意,元数据是每个文件的开销,因此与许多小文件相比,使用非常大的文件将减少元数据的总体大小,从而实现能够将其全部加载到主内存中的目标。
需要注意的是 Haystack 有两种不同类型的元数据:
- 应用程序元数据:描述构建浏览器可用于检索照片的 URL 所需的信息。
- 文件系统元数据:标识主机检索驻留在该主机磁盘上的照片所需的数据。
Haystack 架构由 3 个核心组件组成:Haystack Store、Haystack Directory和Haystack Cache。
简要介绍一下每个组件:
- Haystack Store负责封装图像的持久存储文件系统,并且是唯一处理文件系统元数据的组件。Store 的容量是按物理卷组织的,例如,10 TB 的容量被组织成 100 个物理卷,每个物理卷提供 100 GB 的存储空间。物理卷被分组到逻辑卷中,因此当要存储映像时,它会被复制到同一逻辑卷中的所有物理卷。这种冗余可以减少由于硬盘驱动器故障、磁盘控制器错误等造成的数据丢失。
- Haystack Directory维护逻辑卷与其对应的物理卷以及其他应用程序元数据之间的映射,例如存储每个映像的逻辑卷和具有可用存储空间的逻辑卷。
- Haystack Cache用作内部 CDN,保护 Haystack Store 免受对最流行图像的请求的影响,并在上游 CDN 节点出现故障并需要重新获取内容时提供隔离(通常称为缓存踩踏)。
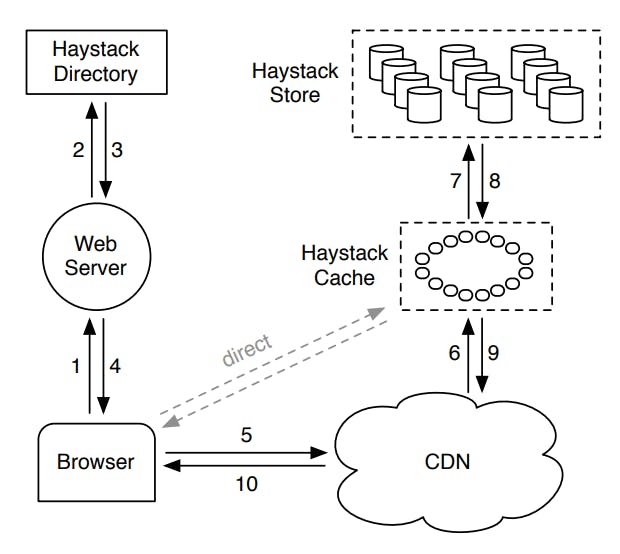
上图显示了所有 3 个组件如何交互以服务流量(热流量和长尾流量),如下所示:
- 浏览器向后端 Web 服务器发送 HTTP 请求以获取图像。
- 后端服务器与 Haystack 目录通信以获取请求图像的 URL。
- Haystack 目录查找其应用程序元数据并获取所请求图像的 URL 并将其发送回后端服务器。请记住,目录是存储每个文件的位置。
- 后端服务器将图像 URL 返回给浏览器。
- 浏览器要么从 CDN 请求图像,要么根据返回 URL 中提供的信息直接请求 Haystack 缓存(我们将在稍后讨论)。
- CDN 在其缓存中查找图像并在缓存命中的情况下将其提供回来,但在缓存未命中的情况下,它会回退到 Haystack 缓存。
- Haystack 缓存在其自己缓存中查找图像,并在缓存命中的情况下将其提供回 CDN,但在缓存未命中的情况下,它会回退到 Haystack Store。
- 获取的图像从 Haystack Store 返回到 Haystack Cache,在那里它被缓存(或不基于一些稍后讨论的逻辑)。
- Haystack Cache 将图像返回给 CDN。
- CDN 缓存图像并将其返回给浏览器。
现在我们来看看Haystack Directory生成的URL,一般长这样:
https://<CDN>/<Cache>/<Machine id>/<Logical volume, photo>
URL的第一部分指定从哪个CDN请求照片。CDN只能使用URL的最后一部分(逻辑卷和照片id)在内部查找照片。如果CDN找不到照片,则会从URL中删除CDN地址并与缓存联系。缓存会执行类似的查找来查找照片,如果找不到,则会从URL中删除缓存地址,并从指定的存储计算机请求照片。另一方面,直接到缓存的请求具有类似的工作流,只是URL缺少CDN特定的信息。
评估
让我们看看 Haystack 是否真的实现了:
- 高吞吐量和低延迟:Haystack 通过每次读取最多需要一个磁盘操作来实现高吞吐量和低延迟,这可以通过最小化元数据大小并将其加载到主内存中来实现。基于论文中完成的基准测试,它还能够实现 4X 每秒每 TB 可用存储的标准化读取率更高。
- 容错:Haystack 通过将每个图像复制到 3 个地理位置不同的位置来实现容错。这种复制保证了当一台主机宕机时,它可以在修复期间被另一台主机替换,并保持零宕机时间。
- 成本效益:Haystack 在我们提到的每个可用 TB 成本的两个维度上都实现了成本效益~28% 少和流程 ~4X 每秒读取数比 NAS 设备上的同等 TB 多。
- 简单性:Haystack 通过采用大多数直接的方法来解决问题来实现简单性,这使得开发速度更快,更易于操作和维护。
详细点击标题